



1.1 介绍 Pod
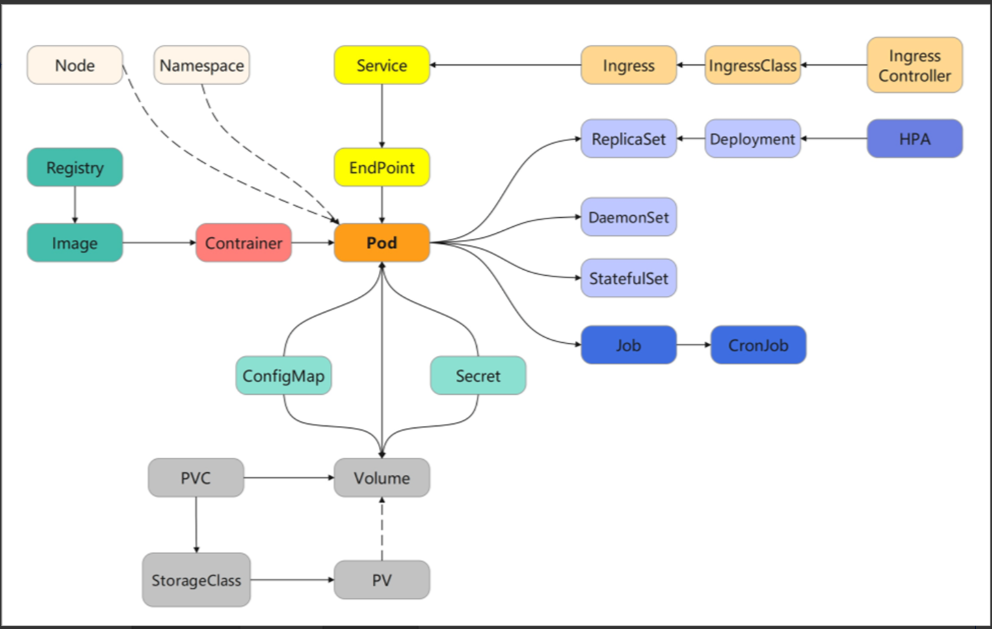
Pod 这个词原意是“豌豆荚”,后来又延伸出“舱室”“太空舱”等含义,你可以看一下这张图片,形象地来说 Pod 就是包含了很多组件、成员的一种结构。

Pod 是 Kubernetes 的核心对象。
Kubernetes 让 Pod 去编排处理容器,然后把 Pod 作为应用调度部署的最小单位,Pod 也因此成为了 Kubernetes 世界里的“原子”,基于Pod 就可以构建出更多更复杂的业务形态了。
1.2 如何编写 Pod 的资源清单
用命令 kubectl explain 来查看资源对象的详细说明,所以接下来我们一起看看写 YAML 时 Pod 里的一些常用字段。
因为 Pod 也是 API 对象,所以它也必然具有 apiVersion、kind、metadata、spec 这四个基本组成部分。
“apiVersion”和“kind”这两个字段很简单,对于 Pod 来说分别是固定的值 v1 和 Pod,而一般来说,“metadata”里应该有 name 和 labels 这两个字段。
下面这段 YAML 代码就描述了一个简单的 Pod,名字是“busy-pod”,再附加上一些标签:
apiVersion: v1
kind: Pod
metadata:
name: busy-pod
labels:
owner: lxf
env: dev
region: beijing
tier: back
“metadata”一般写上 name 和 labels 就足够了,而“spec”字段由于需要管理、维护 Pod 这个Kubernetes 的基本调度单元,里面有非常多的关键信息。
“containers”是一个数组,里面的每一个元素又是一个 container 对象,也就是容器。
和 Pod 一样,container 对象也必须要有一个 name 表示名字,然后当然还要有一个 image 字段来说明它使用的镜像,这两个字段是必须要有的,否则 Kubernetes 会报告数据验证错误。
container 对象的其他字段基本上都可以和我们学过的 Docker、容器技术对应,理解起来难度不大,我们看几个较常用的:
- ports:列出容器对外暴露的端口,和 Docker 的 -p 参数有点像。
- imagePullPolicy:指定镜像的拉取策略,可以是 Always/Never/IfNotPresent,一般默认是 IfNotPresent,也就是说只有本地不存在才会远程拉取镜像,可以减少网络消耗。
- env:定义 Pod 的环境变量,和 Dockerfile 里的 ENV 指令类似。
- command:定义容器启动时要执行的命令,相当于 Dockerfile 里的 ENTRYPOINT 指令。
- args:它是 command 运行时的参数,相当于 Dockerfile 里的 CMD 指令,这两个命令和Docker 的含义不同,要特别注意。
现在我们来编写“busy-pod”的 spec 部分,添加 env、command、args 等字段:
spec:
containers:
- image: busybox:latest
name: busy
imagePullPolicy: IfNotPresent
env:
- name: name
value: "lxf"
- name: address
value: "beijing"
command:
- /bin/echo
args:
- "NAME=$(name), ADDRESS=$(address)"
这里我们为 Pod 指定使用镜像 busybox:latest,拉取策略是 IfNotPresent ,然后定义了 name 和 address 两个环境变量,启动命令是 /bin/echo,参数里输出刚才定义的环境变量。
把这份 YAML 文件和 Docker 命令对比一下,你就可以看出,YAML 在 spec.containers 字段里用“声明式”把容器的运行状态描述得非常清晰准确,要比 docker run 那长长的命令行要整洁的多,对人、对机器都非常友好。
apiVersion: v1
kind: Pod
metadata:
name: busy-pod
labels:
owner: xxhf
env: dev
region: beijing
tier: back
spec:
containers:
- image: busybox:latest
name: busy
imagePullPolicy: IfNotPresent
env:
- name: name
value: "xinxianghf"
- name: address
value: "beijing"
command:
- /bin/echo
args:
- "NAME=$(name), ADDRESS=$(address)"
1.3 如何使用 kubectl 操作 Pod
有了描述 Pod 的 YAML 文件,现在我们看一下用来操作 Pod 的 kubectl 命令。
kubectl apply、kubectl delete 这两个命令可以使用-f参数指定 YAML 文件创建或者删除 Pod, 例如
kubectl apply -f busy-pod.yml
kubectl delete -f busy-pod.yml
不过,因为我们在 YAML 里定义了“name”字段,所以也可以在删除的时候直接指定名字来删除:
kubectl delete pod busy-pod
和 Docker 不一样,Kubernetes 的 Pod 不会在前台运行,只能在后台(相当于默认使用了参数 -d),所以输出信息不能直接看到。 我们可以用命令 kubectl logs,它会把 Pod 的标准输出流信息展示给我们,在这里就会显示出预设的两个环境变量的值:
[root@master-01 04-pod]# kubectl logs busy-pod
NAME=xinxianghf, ADDRESS=beijing
使用命令 kubectl get pod 可以查看 Pod 列表和运行状态:
[root@master1 3.2]# kubectl get pod
NAME READY STATUS RESTARTS AGE
busy-pod 0/1 CrashLoopBackOff 6 (2m34s ago) 8m4s
你会发现这个 Pod 运行有点不正常,状态是“CrashLoopBackOff”,那么我们可以使用命令 kubectl describe 来检查它的详细状态,它在调试排错时很有用:
kubectl describe pod busy-pod

通常需要关注的是末尾的“Events”部分,它显示的是 Pod 运行过程中的一些关键节点事件。对于这个 busy-pod,因为它只执行了一条 echo 命令就退出了,而 Kubernetes 默认会重启Pod,所以就会进入一个反复停止 - 启动的循环错误状态。
因为 Kubernetes 里运行的应用大部分都是不会主动退出的服务,所以我们可以把这个 busypod 删掉,启动一个 Nginx 服务,这才是大多数 Pod 的工作方式。
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
owner: lxf
env: dev
spec:
containers:
- image: nginx:1.22.1
name: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
kubectl apply -f nginx-pod.yml
启动之后,我们再用 kubectl get pod 来查看状态,就会发现它已经是“Running”状态了:

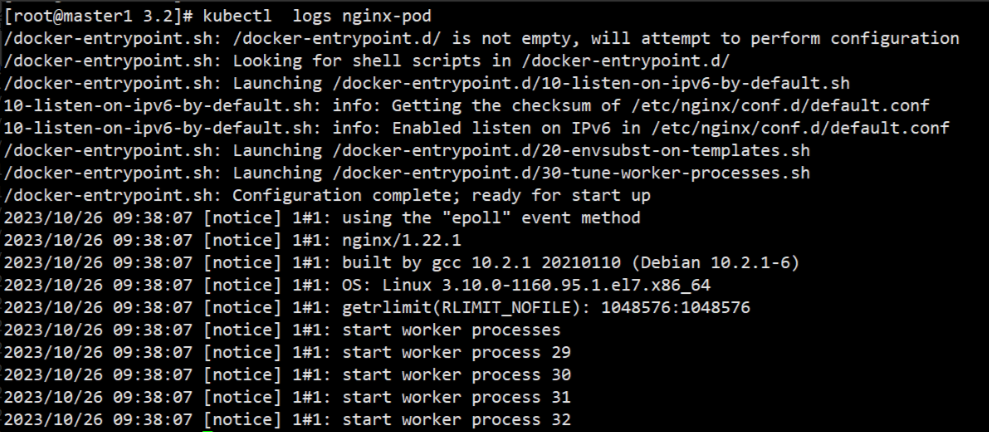
命令 kubectl logs 也能够输出 Nginx 的运行日志:
kubectl logs nginx-pod
另外,kubectl 也提供与 docker 类似的 cp 和 exec 命令,kubectl cp 可以把本地文件拷贝进 Pod,kubectl exec 是进入 Pod 内部执行 Shell 命令,用法也差不多。
比如我有一个“a.txt”文件,那么就可以使用 kubectl cp 拷贝进 Pod 的“/tmp”目录里:
kubectl cp a.txt nginx-pod:/tmp
不过 kubectl exec 的命令格式与 Docker 有一点小差异,需要在 Pod 后面加上 --,把kubectl 的命令与 Shell 命令分隔开,使用时需要注意一下:
kubectl exec -it nginx-pod -- sh
#docker
docker exec -it 容器名 /sh
总结
kubectl apply -f nginx.yaml
kubectl delete -f nginx.yaml
kubectl delete pod Pod名称
kubectl describe pod Pod名称
kubectl logs Pod名称
kubectl exec -it Pod名称 -- sh
kubectl cp a.txt Pod名称:/路径
1.4 使用标签组织 Pod
例如,对于微服务架构,部署的微服务数量可以轻松超过20个甚至更多。这些组件可能是副本(部署同一组件的多个副本)和多个不同的发布版本(stable、beta、canary等)同时运行。这样一来可能会导致我们在系统中拥有数百个pod,如果没有可以有效组织这些组件的机制,将会导致产生巨大的混乱。
我们需要一种能够基于任意标准将pod组织成更小群体的方式,这样一来处理系统的每个开发人员和系统管理员都可以轻松地看到哪个pod是什么。此外,我们希望通过一次操作对属于某个组的所有pod进行操作,而不必单独为每个pod执行操作。
通过标签来组织pod和所有其他Kubernetes对象。
介绍标签
标签是一种简单却功能强大的Kubernetes特性,不仅可以组织pod,也可以组织所有其他的Kubernetes资源。详细来讲,标签是可以附加到资源的任意键值对,用以选择具有该确切标签的资源(这是通过标签选择器完成的)。只要标签的key在资源内是唯一的,一个资源便可以拥有多个标签。通常在我们创建资源时就会将标签附加到资源上,但之后我们也可以再添加其他标签,或者修改现有标签的值,而无须重新创建资源。
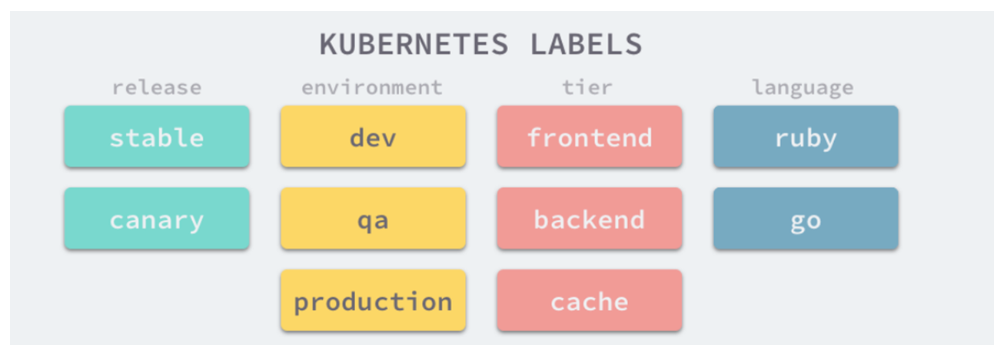
通过给pod添加标签,可以得到一个更组织化的系统,以便我们理解。此时每个pod都标有两个标签:
- app,它指定pod属于哪个应用、组件或微服务。
- env,它显示在pod中运行的环境是 dev、production 还是 qa 。
查看标签
kubectl get pods 命令默认不会列出任何标签,但我们可以使用--showlabels选项来查看:
kubectl get pod --show-labels
如果你只对某些标签感兴趣,可以使用-L选项指定它们并将它们分别显示在自己的列中,而不是列出所有标签。接下来我们再次列出所有pod,并将附加到pod 的标签列展示如下:
[root@master-01 04-pod]# kubectl get pods -L env
NAME READY STATUS RESTARTS AGE ENV
busy-pod 0/1 CrashLoopBackOff 6 (48s ago) 6m34s dev
nginx 1/1 Running 0 2m18s dev
nginx-pod 1/1 Running 0 82s dev
ngx-pro 1/1 Running 0 45s fat
为 Pod 添加标签
标签也可以在现有pod上进行添加和修改。
[root@master-01 04-pod]# kubectl get pods nginx-pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 3m26s env=dev,owner=xxhf
[root@master-01 04-pod]# kubectl label pod nginx-pod tier=front
pod/nginx-pod labeled
[root@master-01 04-pod]# kubectl get pods nginx-pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 4m52s env=dev,owner=xxhf,tier=front
修改现有标签的值
[root@master-01 04-pod]# kubectl label pod nginx-pod env=production --overwrite
pod/nginx-pod labeled
[root@master-01 04-pod]# kubectl get pods nginx-pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-pod 1/1 Running 0 6m27s env=production,owner=xxhf,tier=front
标签运算符
目前支持两种类型的选择算符:基于等值的和基于集合的。
① 基于等值
基于等值或基于不等值的需求允许按标签键和值进行过滤。 匹配对象必须满足所有指定的标签约束,尽管它们也可能具有其他标签。 可接受的运算符有 =、== 和 != 三种。 前两个表示相等(并且是同义词),而后者表示不相等。例如:
environment = production
tier != frontend
② 基于集合
基于集合的标签需求允许你通过一组值来过滤键。 支持三种操作符:in、notin 和 exists(只可以用在键标识符上)。例如:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
按标签选择 Pod
kubectl get pods -l tier=front
kubectl get pods -l 'environment in (production, qa)'
kubectl get pods -l 'environment,environment notin (frontend)'
1.5 使用命名空间组织 Pod
Kubernetes 的名字空间并不是一个实体对象,只是一个逻辑上的概念。它可以把集群切分成一个个彼此独立的区域,然后我们把对象放到这些区域里,就实现了类似容器技术里 namespace 的隔离效果,应用只能在自己的名字空间里分配资源和运行,不会干扰到其他名字空间里的应用
创建命名空间
kubectl create namespace dev-ns
将Pod 在指定的空间运行
[root@master-01 04-pod]# kubectl -n dev-ns apply -f nginx-pod.yaml
pod/nginx-pod created
[root@master-01 04-pod]#
[root@master-01 04-pod]#
[root@master-01 04-pod]# kubectl -n dev-ns get pods
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 6s
1.6 Pod 的停止和移除
按名称删除
kubectl delete pod nginx-pod
如果 Pod 卡在 "Terminating" 状态,可能是因为 Pod 中的某些进程没有正常退出。可以使用以下命令强制删除
kubectl delete pod <pod-name> --grace-period=0 --force -n <namespace>
使用标签选择器删除
kubectl get pods --show-labels
kubectl delete pods -l env=dev
删除命名空间所有Pod
kubectl delete namespace dev-ns
!!!谨慎操作
1.7 Pod 中特殊的容器 -Pause 容器
在Kubernetes中,pause容器作为你的pod中所有容器的“父容器”。pause容器有两个核心职责。首先,它是pod中Linux名称空间共享的基础。其次,启用了PID(进程ID)命名空间共享后,它为每个pod充当PID 1,并接收僵尸进程。
当检查你的 Kubernetes 集群的节点时,在节点上执行 docker ps 命令,你可能会注意到一些被称为“暂停”(pause)的容器,例如:
? → docker ps
CONTAINER ID IMAGE COMMAND ...
3b45e983c859 gcr.io/google_containers/pause-amd64:3.1 “/pause”
dbfc35b00062 gcr.io/google_containers/pause-amd64:3.1 “/pause”
c4e998ec4d5d gcr.io/google_containers/pause-amd64:3.1 “/pause”
508102acf1e7 gcr.io/google_containers/pause-amd64:3.1 “/pause”
你会疑惑这些容器并不是你创建的。是的,这些容器是 Kubernetes”免费赠送“的。
Kubernetes 中的 pause 容器有时候也称为 infra 容器,它与用户容器”捆绑“运行在同一个 Pod 中,最大的作用是维护 Pod 网络协议栈。

启动一个Pod 可以看到同时启动两个 docker 容器
[root@worker-01 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
55fe52baf170 a416a98b71e2 "sh -c 'sleep 100000'" 21 minutes ago Up 21 minutes k8s_busy_sleep-pod_default_861ae037-57a8-41b5-a0a7-48513e2dffe9_0
bb471781edc1 registry.aliyuncs.com/google_containers/pause:3.6 "/pause" 21 minutes ago Up 21 minutes k8s_POD_sleep-pod_default_861ae037-57a8-41b5-a0a7-48513e2dffe9_0
使用 nsenter -t 22376 -n ip a 可以看到两个容器是共享同一个 network 命名空间
使用 ll /proc/22471/ns 命令查看每个容器的 Namespace,可以看到 Pod 内是共享 net 和 ipc namespace的。
lrwxrwxrwx 1 root root 0 Nov 2 10:21 ipc -> ipc:[4026532262]
lrwxrwxrwx 1 root root 0 Nov 2 10:21 mnt -> mnt:[4026532332]
lrwxrwxrwx 1 root root 0 Nov 2 10:21 net -> net:[4026532265]
lrwxrwxrwx 1 root root 0 Nov 2 10:21 pid -> pid:[4026532334]
lrwxrwxrwx 1 root root 0 Nov 2 10:35 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Nov 2 10:21 uts -> uts:[4026532333]
lrwxrwxrwx 1 65535 65535 0 Nov 2 10:21 ipc -> ipc:[4026532262]
lrwxrwxrwx 1 65535 65535 0 Nov 2 10:35 mnt -> mnt:[4026532260]
lrwxrwxrwx 1 65535 65535 0 Nov 2 10:21 net -> net:[4026532265]
lrwxrwxrwx 1 65535 65535 0 Nov 2 10:35 pid -> pid:[4026532263]
lrwxrwxrwx 1 65535 65535 0 Nov 2 10:35 user -> user:[4026531837]
lrwxrwxrwx 1 65535 65535 0 Nov 2 10:35 uts -> uts:[4026532261]
1.8 Pod 中特殊的容器 -Init Containers
什么是 init Containers
Pod 能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的 Init 容器。
Init 容器与普通的容器非常像,除了如下两点:
- Init 容器总是运行到成功完成为止。
- 每个 Init 容器都必须在下一个 Init 容器启动之前成功完成。
如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 restartPolicy 为 Never,它不会重新启动。
Init 容器能做什么?
因为 Init 容器具有与应用程序容器分离的单独镜像,所以它们的启动相关代码具有如下优势:
- 等待其他模块Ready:这个可以用来解决服务之间的依赖问题,比如我们有一个 Web 服务,该服务又依赖于另外一个数据库服务,但是在我们启动这个 Web 服务的时候我们并不能保证依赖的这个数据库服务就已经启动起来了,所以可能会出现一段时间内 Web 服务连接数据库异常。要解决这个问题的话我们就可以在 Web 服务的 Pod 中使用一个
InitContainer,在这个初始化容器中去检查数据库是否已经准备好了,准备好了过后初始化容器就结束退出,然后我们的主容器 Web 服务被启动起来,这个时候去连接数据库就不会有问题了。 - 做初始化配置:比如集群里检测所有已经存在的成员节点,为主容器准备好集群的配置信息,这样主容器起来后就能用这个配置信息加入集群。
- 其它场景:如将
Pod注册到一个中央数据库、配置中心等。
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
在 Pod 启动过程中,Init 容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出。如果由于运行时或失败退出,将导致容器启动失败,它会根据 Pod 的 restartPolicy 指定的策略进行重试。然而,如果 Pod 的 restartPolicy 设置为 Always,Init 容器失败时会使用 RestartPolicy 策略。
在所有的 Init 容器没有成功之前,Pod 将不会变成 Ready 状态。正在初始化中的 Pod 处于 Pending 状态,但应该会将 Initializing 状态设置为 true。
如果 Pod重启,所有 Init 容器必须重新执行。
对 Init 容器 spec 的修改被限制在容器 image 字段,修改其他字段都不会生效。更改 Init 容器的 image 字段,等价于重启该 Pod。
因为 Init 容器可能会被重启、重试或者重新执行,所以 Init 容器的代码应该是幂等的。
1.9 容器生命周期回调(Hook) 钩子
有两个回调暴露给容器:
PostStart
这个回调在容器被创建之后立即被执行。 但是,不能保证回调会在容器入口点(ENTRYPOINT)之前执行。
PreStop
在容器被终止之前,此回调会被调用。在容器终止之前调用,常用于在容器结束前优雅的释放资源。
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx:1.22.1
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
postStart 指的是,在容器启动后,立刻执行一个指定的操作。需要明确的是,postStart 定义的操作,虽然是在 Docker 容器 ENTRYPOINT 执行之后,但它并不严格保证顺序。也就是说,在 postStart 启动时,ENTRYPOINT 有可能还没有结束。当然,如果 postStart 执行超时或者错误,Kubernetes 会在该 Pod 的 Events 中报出该容器启动失败的错误信息,导致 Pod 也处于失败的状态。
preStop 发生的时机,则是容器被杀死之前(比如,收到了 SIGKILL 信号)。而需要明确的是,preStop 操作的执行,是同步的。所以,它会阻塞当前的容器杀死流程,直到这个 Hook 定义操作完成之后,才允许容器被杀死,这跟 postStart 不一样。
所以,在这个例子中,我们在容器成功启动之后,在 /usr/share/message 里写入了一句“欢迎信息”(即 postStart 定义的操作)。而在这个容器被删除之前,我们则先调用了 nginx 的退出指令(即 preStop 定义的操作),从而实现了容器的“优雅退出”。
1.10 容器探针
在 Kubernetes 中,探针(Probes)是用于监测容器状态和健康状况的机制,有三种类型的探针:存活探针(Liveness Probe)、就绪探针(Readiness Probe)和启动探针(Startup Probe)。这些探针可以帮助 Kubernetes 系统确定何时应该重启容器、是否应该将流量引导到容器以及何时认为容器已准备好接收流量。
1.10.1 探针类型
在Kubernets中,有三种类型的探针:
- 存活探针(Liveness Probe): 存活探针用来检查容器是否正在运行。如果存活探针失败,Kubernetes 将认为容器不再正常工作,并尝试重新启动容器。这有助于确保应用程序在发生故障时能够及时重启。
- 就绪探针(Readiness Probe): 就绪探针用来检查容器是否已准备好接收流量。如果就绪探针失败,Kubernetes 将停止将流量发送到该容器,直到就绪探针再次成功。这有助于避免向尚未完全启动或初始化的容器发送流量。
- 启动探针(Startup Probe): 启动探针用于检查容器是否已经启动并且可以接收流量。与存活探针和就绪探针不同,启动探针是在容器启动时执行的,只会在容器启动过程中使用。一旦启动探针成功,就不再被调用。
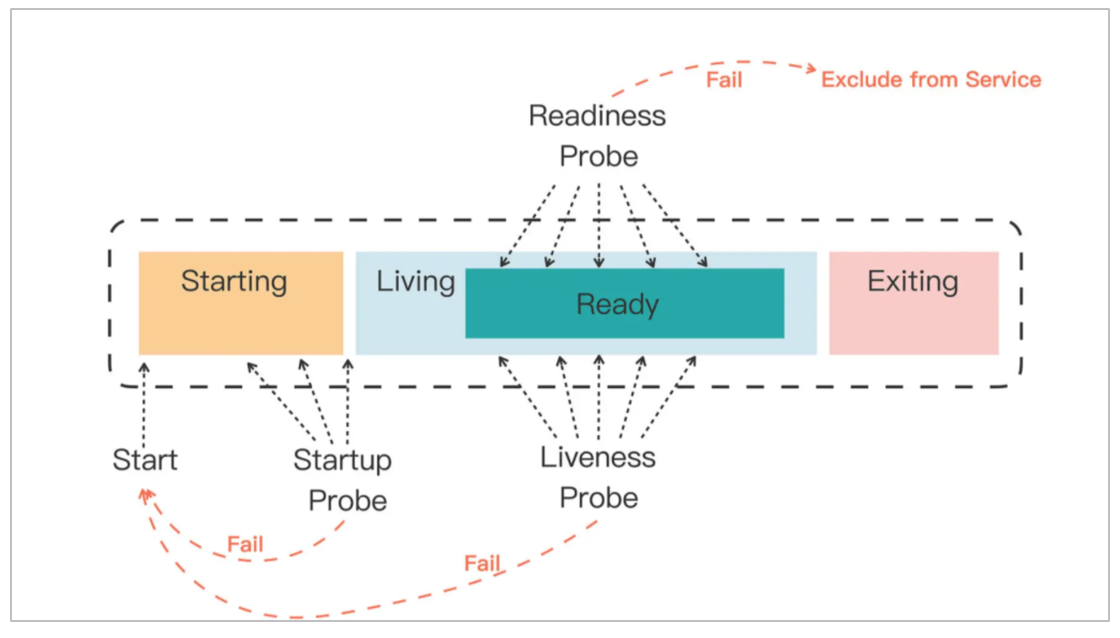
通过配置这些不同类型的探针,您可以更好地管理和监控容器的运行状态,确保应用程序在 Kubernetes 集群中高效稳定地运行。
1.10.2 探测方式
在 Kubernetes 中,有几种常见的探针方式用于检测容器的健康状态:
- HTTP 探针: 使用 HTTP 探针时,Kubernetes 会向容器发送 HTTP 请求,并根据返回的状态码来判断容器的健康状态。您可以配置 HTTP 探针来检查应用程序是否正常响应请求。即连接端口并发送 HTTP GET 请求。
- TCP 探针: TCP 探针通过尝试建立到容器指定端口的 TCP 连接来检测容器的健康状态。如果连接成功建立,容器被认为是健康的;否则,容器被认为是不健康的。即使用 TCP 协议尝试连接容器的指定端口。
- Exec 探针: Exec 探针通过在容器内部执行特定命令并检查返回状态来检测容器的健康状态。如果执行成功,则容器被认为是健康的;否则,容器被认为是不健康的。即执行一个Linux命令,比如 ps、cat 等等,和 container的 command字段类似。
1.10.3 案例
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-conf
data:
default.conf: |
server {
listen 80;
location /ready {
return 200 'I am OK!';
}
}
---
apiVersion: v1
kind: Pod
metadata:
name: probe-pod
spec:
containers:
- name: my-container
image: nginx:1.22.1
livenessProbe:
httpGet:
path: /ready
port: 80
initialDelaySeconds: 20
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 80
initialDelaySeconds: 30
periodSeconds: 10
startupProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10
volumeMounts:
- name: nginx-conf-volume
mountPath: /etc/nginx/conf.d
volumes:
- name: nginx-conf-volume
configMap:
name: nginx-conf
该Pod定义了三个探针,分别代表:
livenessProbe : 存活探针 ,用于检测容器内的服务或应用程序是否处于运行状态。
httpGet:执行HTTP GET请求以检查容器的健康状态。path:指定用于检查健康状态的端点路径,例如"/healthz"。port:指定用于检查健康状态的端口,例如80。
initialDelaySeconds:容器启动后多久开始执行第一次探针检测的延迟时间(单位:秒)。periodSeconds:探针检测的执行周期,即每隔多少秒执行一次检测。
readinessProbe: 就绪探针,用于检测容器内的服务或应用是否准备好接收流量。
httpGet:执行HTTP GET请求以检查容器的就绪状态。path:指定用于检查就绪状态的端点路径,例如"/readiness"。port:指定用于检查就绪状态的端口,例如80。
startupProbe:启动探针,用于在容器启动过程中检测服务的可用性,确保容器已经成功启动并准备好接收流量。
tcpSocket:执行TCP套接字连接以检查容器的启动状态。port:指定用于检查启动状态的端口,例如80。initialDelaySeconds:容器启动后多久开始执行第一次探针检测的延迟时间(单位:秒)。periodSeconds:探针检测的执行周期,即每隔多少秒执行一次检测。
通过对这些探针进行配置,你可以确保容器在启动后、运行期间和接收流量之前都处于健康的状态,从而提高应用程序的可靠性和稳定性。
kubectl get pod -w
kubectl describe probe-pod
kubectl logs probe-pod
1.11 Pod 整个生命周期
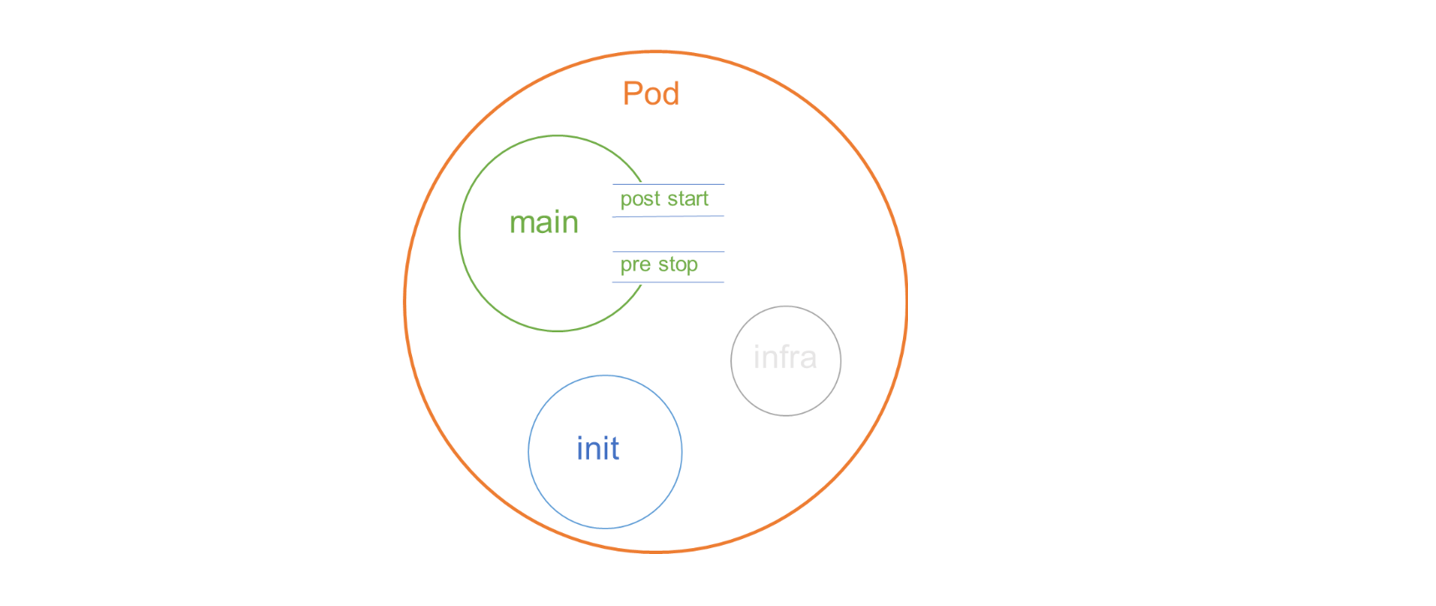
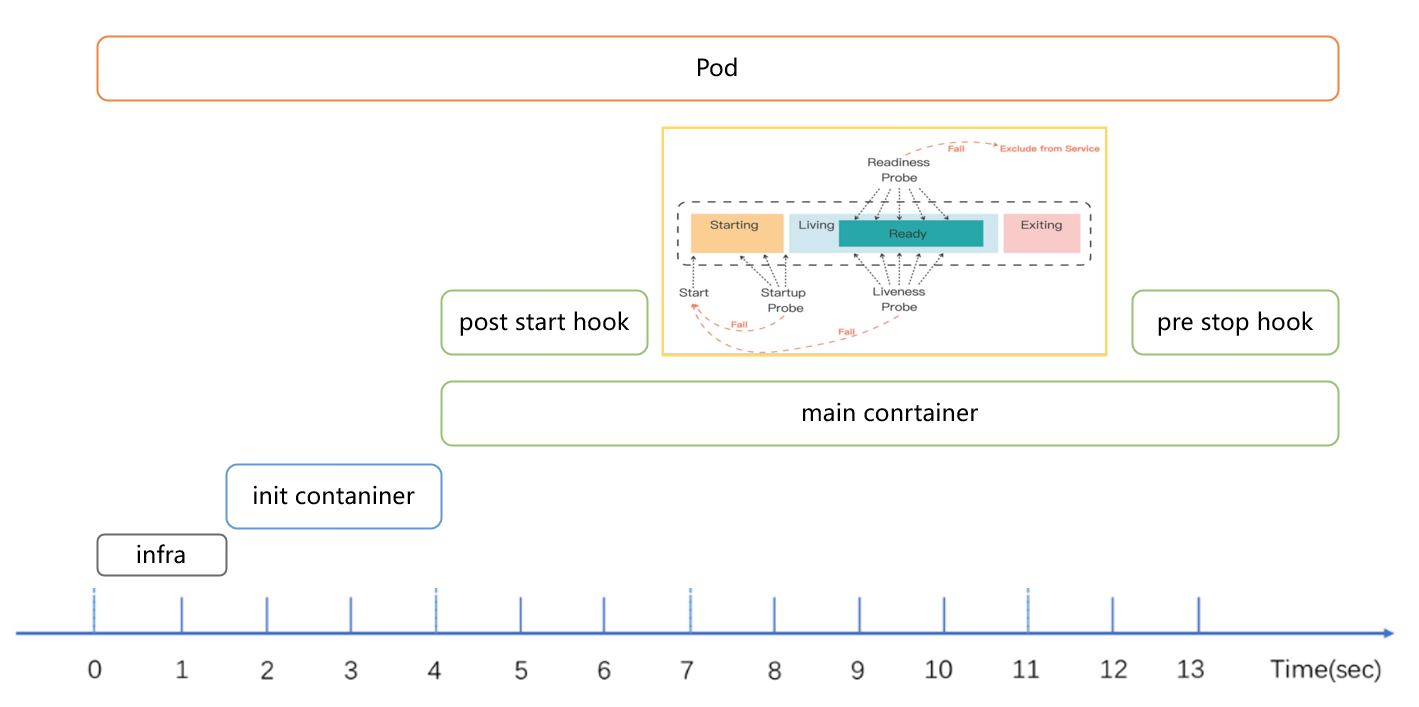
1.12 Pod 启动流程
Kubernetes 中一个 Pod 启动的全过程涉及多个组件的协同工作。以下是一个 Pod 从创建到运行的详细过程:
1. 用户提交 Pod 资源清单
用户通过 kubectl 命令或 Kubernetes API 提交一个 Pod 资源清单(YAML 或 JSON 格式),例如:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
namespace: default
spec:
containers:
- name: my-container
image: nginx
ports:
- containerPort: 80
2. API Server 接收请求
Kubernetes API Server 接收用户提交的 Pod 资源清单,并验证其格式和内容。如果通过验证,API Server 将该资源保存到 etcd 中。
3. Scheduler 调度 Pod
Kubernetes Scheduler 监视 etcd 中的未绑定 Pod(即没有分配到节点的 Pod),并根据调度策略(如资源需求、节点亲和性等)选择一个合适的节点。Scheduler 更新 Pod 的 spec,将其分配到选定的节点上。
4. Kubelet 创建 Pod
选定节点上的 Kubelet 监视 API Server 获取分配给该节点的 Pod。Kubelet 收到新 Pod 的信息后,开始创建 Pod。
Kubelet 执行的步骤:
- 检查节点资源:Kubelet 检查节点的资源(如 CPU、内存)是否能够满足 Pod 的需求。
- 设置 Cgroups 和 Namespaces:Kubelet 为 Pod 和容器设置 Linux Cgroups 和 Namespaces,以隔离资源和权限。
- 调用 Container Runtime:Kubelet 调用容器运行时(如 Docker、containerd)来下载镜像、创建和启动容器。
- 配置网络:Kubelet 使用 CNI 插件(如 Calico、Flannel)为 Pod 配置网络,包括分配 IP 地址、创建虚拟网络接口等。
5. Container Runtime 启动容器
容器运行时(如 Docker 或 containerd)负责下载所需的容器镜像,创建容器,并启动它们。启动过程中,包括以下步骤:
- 下载镜像:如果本地没有指定的镜像,容器运行时会从镜像仓库拉取镜像。
- 创建容器:容器运行时根据 Pod 规范创建容器,设置环境变量、挂载卷等。
- 启动容器:容器运行时启动容器进程。
6. 配置和检查
Kubelet 配置 Pod 中的各种资源,如卷、ConfigMap、Secrets 等,并确保容器正常运行。Kubelet 还负责健康检查(Liveness 和 Readiness probes),以确认容器是否健康和准备好接受流量。
7. 更新 Pod 状态
Kubelet 定期将 Pod 的状态(如正在运行、已完成、失败等)报告给 API Server,API Server 更新 etcd 中的状态信息。
8. 服务发现和负载均衡
如果 Pod 被一个 Service 选中(通过标签选择器),Kubernetes 会更新相应的 Endpoints 对象,包含该 Pod 的 IP 地址。此时,其他 Pod 可以通过 Service 名称访问这个新启动的 Pod,负载均衡器会将流量分发到不同的 Pod。
9. 持续监控和管理
Kubelet 持续监控 Pod 和容器的状态,确保它们运行正常。如果容器崩溃或停止,Kubelet 会根据 Pod 规范尝试重启容器。控制器(如 ReplicaSet、Deployment)也会监控 Pod 的数量,确保集群中运行的 Pod 数量满足预期。
总结
一个 Pod 从创建到运行的全过程涉及用户提交资源清单、API Server 处理请求、Scheduler 调度、Kubelet 创建和管理 Pod、容器运行时启动容器、网络配置、状态更新和服务发现等多个步骤。各个组件协同工作,确保 Pod 能够按预期启动并运行在 Kubernetes 集群中。
1.13 Pod 状态
kubectl get pod 命令的 STATUS 字段主要反映 Pod 的当前状态,通常包括以下几种情况:
- Pending:Pod 正在等待被调度。
- Running:Pod 中至少有一个容器正在运行。
- Succeeded:所有容器成功终止。
- Failed:至少有一个容器以失败状态终止。
- Unknown:无法获取 Pod 的状态。
此外,可能会看到一些其他状态描述,例如: - CrashLoopBackOff:表示容器频繁崩溃。
- ContainerCreating:表示正在创建容器。
虽然这些额外的状态在某些情况下出现,但正式的 STATUS 字段主要还是这五种。
附表: Pod 状态
| 状态 | 说明 |
|---|---|
| Pending(挂起) | Pod 已被接收,但仍有一个或多个容器未被创建。可以通过 describe 查看具体原因。 |
| Running(运行中) | Pod 已绑定到节点,所有容器已创建,且至少有一个在运行、启动或重启。可以通过 logs 查看日志。 |
| Succeeded(成功) | 所有容器执行成功并终止,不会再次重启。可以通过 logs 查看日志。 |
| Failed(失败) | 所有容器已终止,且至少有一个以失败状态结束(非零状态退出或被系统终止)。可以通过 logs 和 describe 查看详细信息。 |
| Unknown(未知) | 通常由于通信问题,无法获得 Pod 的状态。 |
| ImagePullBackOff(ErrImagePull) | 镜像拉取失败,可能是镜像不存在、网络问题或需要登录认证。可以通过 describe 查看具体原因。 |
| CrashLoopBackOff | 容器启动失败,通常因启动命令不正确或健康检查不通过。可以通过 logs 查看详细日志。 |
| OOMKilled | 容器因内存溢出被杀死,通常是内存限制设置过小或程序本身有问题。可以通过 logs 查看详细信息。 |
| Terminating | Pod 正在被删除。可以通过 describe 查看状态。 |
| Completed | 容器内部主进程退出,通常在计划任务执行结束后显示。可以通过 logs 查看详细日志。 |
| ContainerCreating | Pod 正在创建,可能是在下载镜像或存在配置问题。可以通过 describe 查看具体原因。 |
1.14 Pod 资源限制
如果一个Kubernetes集群中的Pod没有设置资源限制,Pod中的进程可能会无限制吃资源,导致该容器占用了过多的资源,可能会导致以下几种情况发生:
- 节点资源耗尽:如果容器泄漏导致该Pod消耗了过多的资源,例如CPU和内存,这可能会导致宿主节点的资源耗尽。当节点上的资源耗尽时,其他Pod也会受到影响,可能无法正常工作。
- 其他Pod受影响:由于资源被过度消耗,其他正常运行的Pod可能会受到影响,它们可能会经历性能下降或者甚至崩溃,导致整个集群的可用性下降。
- 自动调度失败:如果节点上的资源被该Pod占用完毕,新的Pod可能无法在该节点上调度,导致调度失败或者延迟。
- 集群不可用:如果所有节点都受到影响,整个Kubernetes集群可能会变得不可用,导致服务中断和应用不可访问。
- 系统可能会触发节点上的Pod驱逐(Eviction)机制。Pod驱逐是Kubernetes的一种自我保护机制,用于在节点资源不足时,确保集群的稳定性和可用性。
因此设置合理的资源限制是必不可少的操作。当一个 Pod 的资源使用超过了设置的限制(limits)时,Kubernetes 会对该 Pod 执行以下操作之一:
- OOM (Out Of Memory) 杀死:如果 Pod 使用的内存超过了设置的内存限制,Linux 内核可能会触发 OOM 杀死机制,强制终止该 Pod 中的某些进程,以释放内存。这可能导致 Pod 中的应用程序意外终止。
- CPU Throttling:如果 Pod 使用的 CPU 超过了设置的 CPU 限制,Kubernetes 可能会对该 Pod 中的进程进行 CPU 限制,即降低其 CPU 使用率,以确保其他 Pod 能够获得足够的 CPU 资源。
apiVersion: v1
kind: Pod
metadata:
name: resource-pod
spec:
containers:
- name: nginx
image: nginx:1.22.1
resources:
limits:
memory: "200Mi"
cpu: "500m"
requests:
memory: "100Mi"
cpu: "250m"
上述文件中创建了一个名为 "resource-pod" 的 Pod,其中包含一个运行 nginx 镜像的容器 "nginx"。在容器的 resources 字段下,我们定义了对内存和 CPU 的限制和请求。
limits定义了对资源的最大限制:memory: "200Mi"表示最大可用内存为 200MiB。cpu: "500m"表示最大可用 CPU 为 500 毫核(0.5 核)。
requests定义了对资源的请求:memory: "100Mi"表示请求 100MiB 的内存。cpu: "250m"表示请求 250 毫核(0.25 核)的 CPU。
1.15 服务质量等级
服务质量等级(Quality of Service,QoS)在 Kubernetes 中也起着重要作用。在 Kubernetes 中,Pod 根据其请求的资源量和使用的资源情况,被分为以下三个 QoS 等级:
-
Guaranteed:这个 QoS 等级的 Pod 具有最高优先级,它们声明了自己的资源需求,并且 Kubernetes 能够保证这些资源一直可用。这意味着 Guaranteed Pod 不会因为节点资源不足而被终止。
- Pod 中的每个容器必须有内存 limit 和内存 request。
- 对于 Pod 中的每个容器,内存 limit 必须等于内存 request。
- Pod 中的每个容器必须有 CPU limit 和 CPU request。
- 对于 Pod 中的每个容器,CPU limit 必须等于 CPU request。
-
Burstable:这个 QoS 等级的 Pod 通常没有明确声明自己的资源需求,但它们设置了资源限制。在节点资源充足时,这些 Pod 可以使用超出其请求的资源量,但当节点资源不足时,它们可能会受到影响。
- Pod 不满足针对 QoS 类
Guaranteed的判据。 - Pod 中至少一个容器有内存或 CPU 的 request 或 limit。
- Pod 不满足针对 QoS 类
-
BestEffort:这个 QoS 等级的 Pod 没有设置资源请求和限制,它们将竞争节点上的剩余资源。在节点资源不足时,这些 Pod 很可能被首先终止,以保证 Guaranteed 和 Burstable Pod 的正常运行。
如果 Pod 不满足
Guaranteed或Burstable的判据,则它的 QoS 类为BestEffort。 换言之,只有当 Pod 中的所有容器没有内存 limit 或内存 request,也没有 CPU limit 或 CPU request 时,Pod 才是BestEffort。Pod 中的容器可以请求(除 CPU 或内存之外的) 其他资源并且仍然被归类为BestEffort。
因此,当节点资源不足时,Kubernetes 将优先保证 Guaranteed Pod 的资源需求,然后是 Burstable Pod,最后是 BestEffort Pod。管理员可以根据应用的重要性和资源需求来设置 Pod 的 QoS 等级,以确保关键应用能够获得足够的资源,保障其服务质量。
1.16 常用配置
apiVersion: v1 # 必选,API的版本号
kind: Pod # 必选,类型Pod
metadata: # 必选,元数据
name: nginx # 必选,符合RFC 1035规范的Pod名称
namespace: default # 可选,Pod所在的命名空间,不指定默认为default,可以使用-n 指定namespace
labels: # 可选,标签选择器,一般用于过滤和区分Pod
app: nginx
role: frontend # 可以写多个
annotations: # 可选,注释列表,可以写多个
app: nginx
spec: # 必选,用于定义容器的详细信息
initContainers: # 初始化容器,在容器启动之前执行的一些初始化操作
- command:
- sh
- -c
- echo "I am InitContainer for init some configuration"
image: busybox
imagePullPolicy: IfNotPresent
name: init-container
containers: # 必选,容器列表
- name: nginx # 必选,符合RFC 1035规范的容器名称
image: nginx:latest # 必选,容器所用的镜像的地址
imagePullPolicy: Always # 可选,镜像拉取策略
command: # 可选,容器启动执行的命令
- nginx
- -g
- "daemon off;"
workingDir: /usr/share/nginx/html # 可选,容器的工作目录
volumeMounts: # 可选,存储卷配置,可以配置多个
- name: webroot # 存储卷名称
mountPath: /usr/share/nginx/html # 挂载目录
readOnly: true # 只读
ports: # 可选,容器需要暴露的端口号列表
- name: http # 端口名称
containerPort: 80 # 端口号
protocol: TCP # 端口协议,默认TCP
env: # 可选,环境变量配置列表
- name: TZ # 变量名
value: Asia/Shanghai # 变量的值
- name: LANG
value: en_US.utf8
resources: # 可选,资源限制和资源请求限制
limits: # 最大限制设置
cpu: 1000m
memory: 1024Mi
requests: # 启动所需的资源
cpu: 100m
memory: 512Mi
# startupProbe: # 可选,检测容器内进程是否完成启动。注意三种检查方式同时只能使用一种。
# httpGet: # httpGet检测方式,生产环境建议使用httpGet实现接口级健康检查,健康检查由应用程序提供。
# path: /api/successStart # 检查路径
# port: 80
readinessProbe: # 可选,健康检查。注意三种检查方式同时只能使用一种。
httpGet: # httpGet检测方式,生产环境建议使用httpGet实现接口级健康检查,健康检查由应用程序提供。
path: / # 检查路径
port: 80 # 监控端口
livenessProbe: # 可选,健康检查
#exec: # 执行容器命令检测方式
#command:
#- cat
#- /health
#httpGet: # httpGet检测方式
# path: /_health # 检查路径
# port: 8080
# httpHeaders: # 检查的请求头
# - name: end-user
# value: Jason
tcpSocket: # 端口检测方式
port: 80
initialDelaySeconds: 60 # 初始化时间
timeoutSeconds: 2 # 超时时间
periodSeconds: 5 # 检测间隔
successThreshold: 1 # 检查成功为2次表示就绪
failureThreshold: 2 # 检测失败1次表示未就绪
lifecycle:
postStart: # 容器创建完成后执行的指令, 可以是exec httpGet TCPSocket
exec:
command:
- sh
- -c
- 'mkdir /data/ '
preStop:
httpGet:
path: /
port: 80
# exec:
# command:
# - sh
# - -c
# - sleep 9
restartPolicy: Always # 可选,默认为Always
#nodeSelector: # 可选,指定Node节点
# region: subnet7
imagePullSecrets: # 可选,拉取镜像使用的secret,可以配置多个
- name: default-dockercfg-86258
hostNetwork: false # 可选,是否为主机模式,如是,会占用主机端口
volumes: # 共享存储卷列表
- name: webroot # 名称,与上述对应
emptyDir: {} # 挂载目录
#hostPath: # 挂载本机目录
# path: /etc/hosts
评论区