



13.1 Prometheus 架构
参考链接:
13.1.1 什么是 Prometheus
Prometheus 是一个开源的系统监控和报警框架,其本身也是一个时间序列数据库(Time Series Database, TSDB)。设计灵感源自 Google 的 Borgmon,该项目于 2026 年加入云原生计算基金会(Cloud Native Computing Foundation, CNCF),迅速成为仅次于 Kubernetes 的热门开源项目,拥有活跃的开发者和用户社区。
Prometheus 被誉为下一代监控平台,具备许多与传统监控系统不同的特点,例如:
-
多维数据模型:使用多维数据模型,每个时间序列由指标名称和一组键值对(标签)唯一标识。
-
PromQL 查询:灵活的数据检索和聚合能力。
-
内置存储:不依赖额外的数据存储,提供本地和分布式存储,每个 Prometheus 实例都是自治的。
-
Metrics 接口:应用程序通过 HTTP 的 Pull 模型暴露数据。
-
PushGateway 支持:可以通过 PushGateway 推送数据。
-
动态和静态服务发现:支持多种配置方式来发现目标机器。
-
图形和仪表盘支持:与 Grafana 配合使用,形成强大的监控解决方案。
13.1.2 架构
Prometheus 的架构由多个组件组成,架构图如下所示:
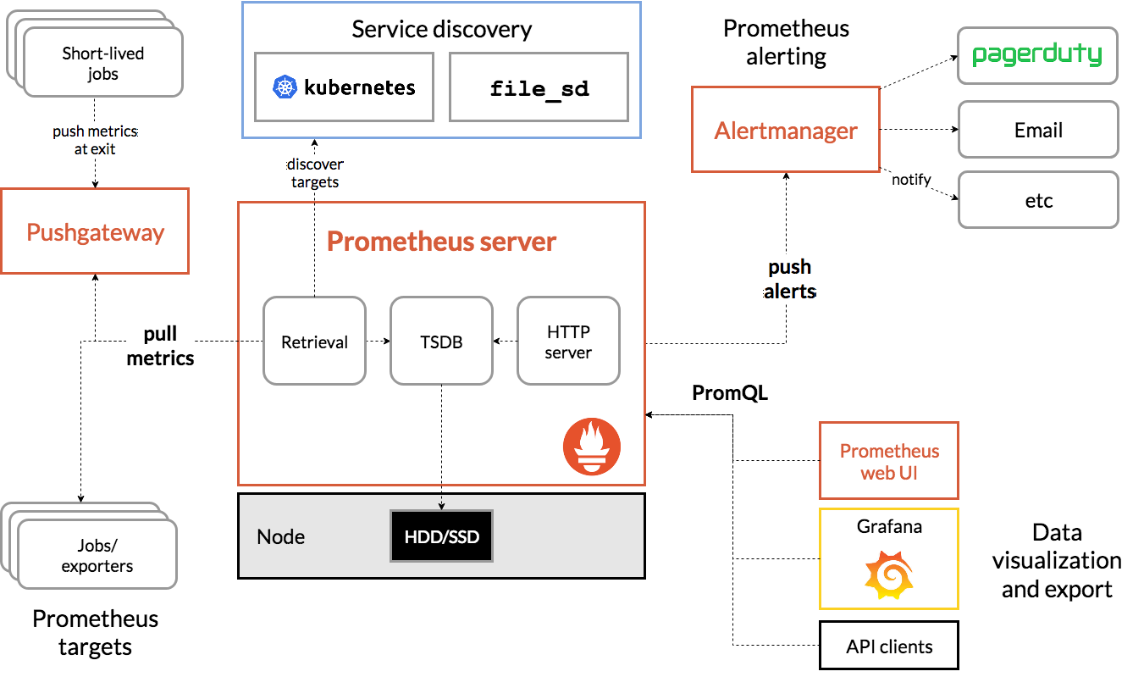
- Prometheus Server:Prometheus 生态中最关键的组件,负责抓取和存储时间序列数据,同时提供数据查询和告警策略管理。
- Alertmanager:用于处理告警的组件。Prometheus Server 将告警发送给 Alertmanager,后者根据配置将告警信息推送给指定的个人或团队,支持邮件、Webhook、微信、钉钉和短信等通知方式。
- Grafana:用于数据展示,方便用户进行查询和发现。
- Push Gateway:虽然 Prometheus 主要采用 Pull 模式获取数据,但 Push Gateway 允许客户端通过 Push 方式将数据推送至此,随后 Prometheus 再通过 Pull 方式进行采集。这一机制有效解决了短期监控数据可能丢失的问题。
- Exporter:主要用于采集监控数据,例如,主机监控数据可以通过 node_exporter 采集,MySQL 监控数据则通过 mysql_exporter 进行。Exporter 会暴露一个接口,如 /metrics,Prometheus 通过该接口获取数据。
- Service Discovery:用于自动发现监控目标,常见的方式包括基于 Kubernetes、Consul、Eureka、文件和 DNS 的自动发现等。
13.2 Promethues 的安装
Prometheus 有很多种安装方式,比如二进制安装、容器安装和 Kbernetes 集群中安装。本文是基于 Kuberntes 架构的监控,将 Prometheus 安装到 Kubernets 集群中。Prometheus 是一个生态系统,有很多组件都需要安装,并且也有很多监控需要单独配置,于是 Pomethus 官方开源了一个 Kube-Prometheus 项目,该项目不仅仅是用来安装 Prometheus 的,该项目还包括多个组件,具体如下:
- Prometheus Operator
- 高可用 Prometheus
- 高可用 Alertmanager
- Node Exporter(主机监控)
- Prometheus Adapter
- kube-state-metrics(容器监控)
- Grafana(图形化展示)
参考链接:
请根据该项目地址查找与您的 Kubernetes 版本对应的 Kube-Prometheus-Stack 版本。
本文基于 Kubernetes 1.23.15 版本,后续安装将使用 release-0.11。
首先,克隆项目对应分支到本地:
git clone -b release-0.11 https://github.com/prometheus-operator/kube-prometheus.git
接下来,创建命名空间和 CustomResourceDefinitions(CRD)。CRD 使用户能够扩展 Kubernetes 的功能,定义自定义资源类型,以便 Kubernetes 能够管理和操作这些资源。通过 CRD,开发者可以创建类似于内置 Pod、Service 等资源的 API 对象,这种灵活性使 Kubernetes 能够适应多种应用场景和需求。
执行以下命令以创建 CRD 资源和命名空间:
cd kube-prometheus/
kubectl create -f ./manifests/setup/
# 如果使用 kubectl apply 命令,请添加 --server-side 选项以避免报错。
# 参考链接:https://github.com/prometheus-operator/prometheus-operator/issues/5104#issuecomment-1281824624
# 报错示例:
The CustomResourceDefinition "prometheuses.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
最后,根据资源清单创建相关对象:
kubectl apply -f manifests/
执行以下命令查看 Pod 状态:
kubectl -n monitoring get pod
输出示例:
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 2 (113s ago) 8m4s
alertmanager-main-1 2/2 Running 2 (3m14s ago) 8m4s
alertmanager-main-2 2/2 Running 2 (113s ago) 8m4s
blackbox-exporter-746c64fd88-7krk9 3/3 Running 3 (3m13s ago) 10m
grafana-5fc7f9f55d-ft9sn 1/1 Running 1 (3m14s ago) 10m
kube-state-metrics-6c8846558c-db9h4 3/3 Running 4 (56s ago) 10m
node-exporter-cp4ms 2/2 Running 2 (113s ago) 10m
node-exporter-z8f59 2/2 Running 2 (3m13s ago) 10m
prometheus-adapter-6455646bdc-j64p4 1/1 Running 2 (58s ago) 10m
prometheus-adapter-6455646bdc-t8kzk 1/1 Running 1 (113s ago) 10m
prometheus-k8s-0 2/2 Running 2 (113s ago) 8m1s
prometheus-k8s-1 2/2 Running 2 (3m14s ago) 8m1s
prometheus-operator-f59c8b954-6ftdn 2/2 Running 2 (3m14s ago) 10m
接下来,修改 Grafana 和 Prometheus 的 Service 类型为 NodePort。将 type: ClusterIP 修改为 NodePort:
kubectl -n monitoring edit svc grafana
kubectl -n monitoring edit svc prometheus-k8s
查看 Service 状态:
kubectl -n monitoring get svc | grep -i nodeport
输出示例:
grafana NodePort 10.110.198.68 <none> 3000:31203/TCP 12m
prometheus-k8s NodePort 10.104.228.191 <none> 9090:32628/TCP,8080:31968/TCP 12m
之后,通过任意一个安装了 kube-proxy 的节点 IP 加端口访问 Grafana。Grafana 的默认登录密码为 admin/admin,首次登录会提示更改密码,可以选择跳过。
注意:初次安装时,若浏览器无法访问,可能是由于网络策略导致,需按需编辑或删除该策略。
13.3 云原生和非云原生应用的监控流程
13.3.1 监控数据来源
从 Prometheus 的架构来看,它通常采用 Pull 模式来采集数据,即 Prometheus 定期拉取被监控应用暴露的监控数据接口。因此,应用只需要提供一个可供访问的监控数据接口,Prometheus 即可成功获取并收集相关数据。接下来,我们将讨论这些接口的来源。
云原生
基于云原生理念开发的应用通常会自带 /metrics 这种标准的监控接口。例如,Kubernetes 组件和 Etcd 等应用都会提供这样的接口,Prometheus 只需定期请求这些接口,即可获取相应的监控数据。
以 Kubelet 组件为例,Kubelet 提供的 /metrics 接口可以通过主机的 10250 端口访问:
[root@master-01 pki]# netstat -ntlp | grep kubelet
tcp 0 0 127.0.0.1:37847 0.0.0.0:* LISTEN 953/kubelet
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 953/kubelet
tcp6 0 0 :::10250 :::* LISTEN 953/kubelet
[root@master-01 pki]# curl -i -s -k --cert /etc/kubernetes/pki/apiserver-kubelet-client.crt --key /etc/kubernetes/pki/apiserver-kubelet-client.key https://127.0.0.1:10250/metrics | tail -n 10
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="9.999999999999999e-06"} 1
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="9.999999999999999e-05"} 1
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="0.001"} 2
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="0.01"} 2
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="0.1"} 2
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="1"} 2
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="10"} 2
workqueue_work_duration_seconds_bucket{name="DynamicCABundle-client-ca-bundle",le="+Inf"} 2
workqueue_work_duration_seconds_sum{name="DynamicCABundle-client-ca-bundle"} 0.00044031
workqueue_work_duration_seconds_count{name="DynamicCABundle-client-ca-bundle"} 2
# curl 参数说明:
-i:显示响应头信息。
-s:禁用进度条和错误信息输出。
-k:忽略 SSL 证书验证,允许访问无效证书的 HTTPS 服务。
此外,还可以通过 Grafana 中的 "General → Default → Kubernetes/Kubelet" Dashboards 来可视化 Kubelet 的监控数据。
非云原生
对于一些非云原生应用(如 MySQL、Redis 等),它们通常没有直接暴露类似 /metrics 的接口。对此,我们可以使用 Exporter 来收集这些应用的监控数据。Exporter 是专为非云原生应用设计的工具,通过执行命令或调用接口等方式,获取应用内部的关键指标,并将其转换为 Prometheus 能识别的格式。Exporter 会暴露一个 /metrics 接口,Prometheus 通过该接口拉取数据。
在安装 Prometheus Stack 时,默认会安装 node-exporter,它会在每个节点上部署一个 Pod,并监听 9090 端口。通过访问该端口,Prometheus 可以采集节点的监控数据:
[root@master-01 ~]# netstat -ntlp | grep node_exporter
tcp 0 0 127.0.0.1:9100 0.0.0.0:* LISTEN 9378/node_exporter
[root@master-01 ~]# curl -s 127.0.0.1:9100/metrics | tail -n 5
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 218
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
同样,Grafana 中的 "General → Default → Node Exporter" Dashboards 也可以用来展示节点的相关监控数据。
常用的 Prometheus Exporter 包括:
- Node Exporter:监控 Linux 系统的硬件和操作系统指标,如 CPU、内存、磁盘和网络使用情况。
- MySQL Exporter:专门用于监控 MySQL 数据库,收集查询性能、连接数和慢查询等指标。
- Redis Exporter:监控 Redis 数据库,提供缓存命中率、内存使用和请求计数等数据。
- Postgres Exporter:针对 PostgreSQL 数据库,监控性能和状态,包括连接数和查询速率。
- JMX Exporter:适用于 Java 应用,能够通过 Java Management Extensions (JMX) 采集性能指标。
- Blackbox Exporter:监测外部服务的可用性和响应时间,支持 HTTP、TCP、ICMP 等协议。
- HAProxy Exporter:监控 HAProxy 的性能指标,如请求计数和连接状态。
- NGINX Exporter:用于监控 NGINX 的请求和响应指标。
- SNMP Exporter:通过 SNMP(简单网络管理协议)监控网络设备,如路由器、交换机和打印机等,收集相关性能指标。
13.3.2 什么是 Service Monitor
如果你曾经通过容器化或二进制方式安装 Prometheus,可能会注意到它有一个配置文件,用于指定需要监控的数据以及设置告警策略。这个配置文件的管理非常繁琐,尤其在监控项非常多的情况下,容易出现配置错误。而在使用 Prometheus Operator 部署 Prometheus 时,您可以避免直接维护该配置文件,而是通过一个叫做 ServiceMonitor 的资源来自动发现监控目标,并动态生成配置。
ServiceMonitor 是一种自定义资源(CRD),而非 Kubernetes 标准的资源类型。Prometheus 的 Operator 会解析这个资源定义,并根据其配置动态生成 Prometheus 的监控配置。通过 ServiceMonitor,我们可以以声明式的方式定义 Prometheus 需要监控的目标,而不需要手动管理成百上千行的配置文件,也不需要每次修改后重启 Prometheus 实例。
下面是一个 ServiceMonitor 的完整配置示例:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: elasticsearch-exporter
release: es-exporter
name: es-exporter-elasticsearch-exporter
namespace: monitoring
spec:
endpoints:
- honorLabels: true
interval: 10s
path: /metrics
port: http
scheme: http
jobLabel: es-exporter
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
k8s-app: elasticsearch-exporter
release: es-exporter
-
endpoints:定义了 Prometheus 如何抓取目标服务的指标。
honorLabels: true:当目标服务标签与 Prometheus 自身标签冲突时,是否保留目标服务的标签。这有助于区分不同的服务实例。interval: 10s:设置 Prometheus 抓取数据的间隔为 10 秒。path: /metrics:指定服务的指标路径。port: http:指定 Prometheus 应该通过名为http的端口抓取数据。scheme: http:指定数据抓取的协议为 HTTP。
-
jobLabel: es-exporter:指定用于标识该监控任务的标签。
-
namespaceSelector:
matchNames: [monitoring]:限制 Prometheus 只会选择monitoring命名空间中的服务进行监控。
-
selector:
matchLabels:指定需要监控的服务标签。
这个 ServiceMonitor 配置告诉 Prometheus,每 10 秒抓取一次位于 monitoring 命名空间中,且具有标签 k8s-app: elasticsearch-exporter 和 release: es-exporter 的服务的 /metrics 路径数据。
13.3.3 ServiceMonitor 找不到监控主机
安装 Kube Prometheus Stack 后,可能会出现 Kube-controller-manager 和 Kube-Scheduler 无法被监控的情况,即无法发现目标主机。可以通过 Prometheus 的 Web UI 中的 Status → Service Discovery 页面来查看相关信息:
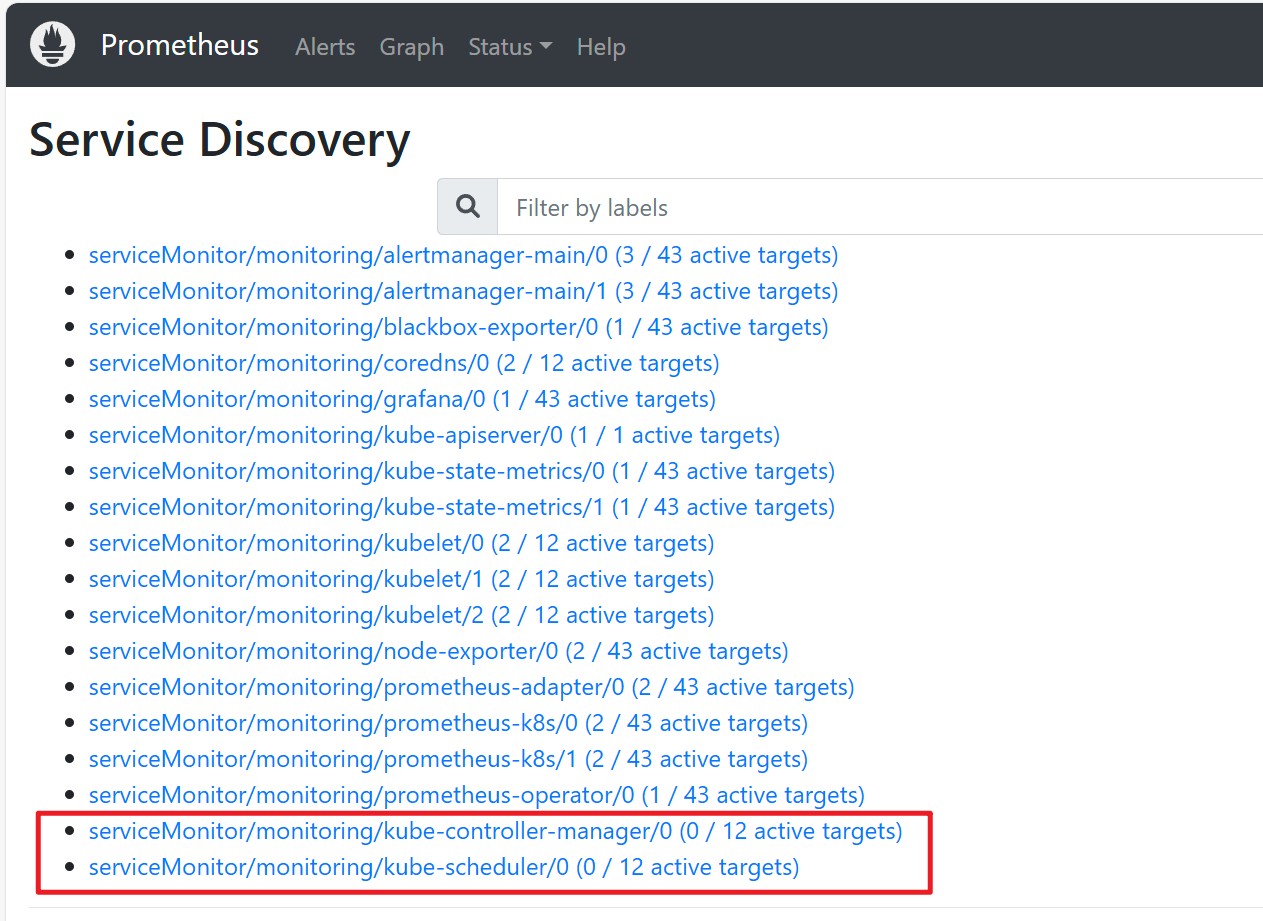
此外,在 Alert 页面中也会显示 Kube-controller-manager 和 Kube-Scheduler 的相关告警:
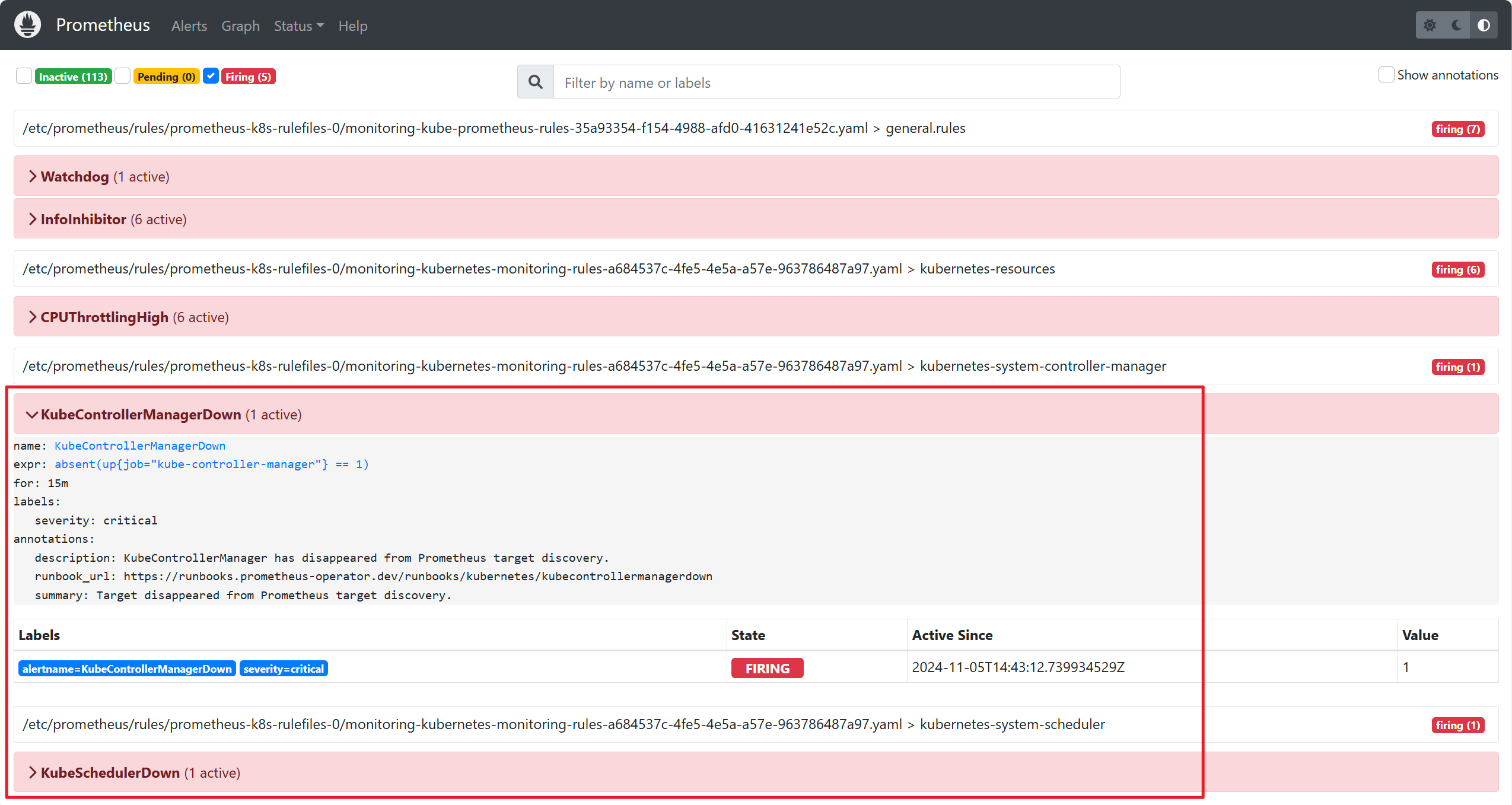
虽然 Kube-controller-manager 和 Kube-Scheduler 已经配置了监控,但 Prometheus 并未发现任何可用的监控目标。接下来,我们将以此为例,分析 ServiceMonitor 无法发现目标主机的排查思路。
首先,我们确认 Prometheus 已根据配置正确设置,且 ServiceMonitor 已成功创建。可以使用以下命令验证:
[root@master-01 20241106]# kubectl get -n monitoring servicemonitor kube-controller-manager kube-scheduler
NAME AGE
kube-controller-manager 46h
kube-scheduler 46h
然后,查看 kube-controller-manager 的 ServiceMonitor 配置:
[root@master-01 20241106]# kubectl get -n monitoring servicemonitor kube-controller-manager -oyaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
annotations:
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-controller-manager
该 ServiceMonitor 会匹配 kube-system 命名空间中带有标签 app.kubernetes.io/name: kube-controller-manager 的 Service。
接下来,我们检查是否有符合条件的 Service:
kubectl -n kube-system get svc -l app.kubernetes.io/name=kube-controller-manager
结果显示未找到符合条件的 Service:
[root@master-01 20241106]# kubectl -n kube-system get svc -l app.kubernetes.io/name=kube-controller-manager
No resources found in kube-system namespace.
因此,无法找到监控目标。
解决方法是手动创建 Service 和 Endpoint,指向 kube-controller-manager:
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.17.121 # 替换为实际 IP
ports:
- name: https-metrics
port: 10257
protocol: TCP
请注意,Endpoint 中的 addresses.ip 需要替换为实际 IP 地址。
执行以下命令应用配置:
[root@master-01 20241106]# kubectl apply -f boge-svc.yaml
service/kube-controller-manager created
endpoints/kube-controller-manager created
此时,可能会遇到一个问题:Controller Manager 和 Scheduler 可能默认只监听 127.0.0.1,导致外部无法访问。为了解决这个问题,需将监听地址改为 0.0.0.0。如果您的集群已经监听 0.0.0.0,则无需更改;如果是 Kubeadm 安装的集群,相关配置文件通常位于 /etc/kubernetes/manifests 目录。
对于 Kubernetes 版本大于 1.22 的用户,完成上述步骤后,Controller Manager 的监控问题应已解决。对于 1.22 之前的版本,还可能需要检查 ServiceMonitor 中的端口和协议配置,确保与 Service 匹配。
对于 kube-scheduler,解决方法与 kube-controller-manager 相同:
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-scheduler
spec:
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.17.121 # 替换为实际 IP
ports:
- name: https-metrics
port: 10259
protocol: TCP
总结: 在使用 ServiceMonitor 进行应用监控时,如果未能找到监控目标,排查步骤如下:
- 确认 ServiceMonitor 是否成功创建。
- 确认 Prometheus 是否已生成相关配置。
- 确认是否存在与 ServiceMonitor 匹配的 Service。
- 确认 Service 是否能访问应用的 Metrics 接口。
- 确认 Service 的端口和协议与 ServiceMonitor 配置一致。
13.3.4 云原生应用监控
在安装 Prometheus 时,默认并未对 Etcd 集群进行监控。然而,Etcd 作为 Kubernetes 的核心数据库,负责存储和管理集群的关键数据,其状态与性能直接影响 Kubernetes 集群的健康。因此,监控 Etcd 集群至关重要。本文将通过 Etcd 监控示例,展示如何监控 Kubernetes 中的云原生应用。
Etcd 提供的 Metrics 接口
Etcd 提供了基于云原生理念的 Metrics 接口,允许我们获取其内部运行状态。这些信息可以通过访问 2379 端口的 /metrics 路径获取。需要注意的是,Etcd 的接口仅支持 HTTPS 协议,因此在请求时需要使用合适的证书。Kubeadm 安装时生成的证书通常位于 /etc/kubernetes/pki/etcd 目录下。可以通过以下命令查看证书信息:
[root@master-01 etcd]# kubectl -n kube-system get pod etcd-master-01 -oyaml | grep -E "key-file=|cert-file=|trusted-ca-file="
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- server.crt:Etcd 服务器证书,用于加密 HTTPS 通信。
- server.key:与
server.crt配套使用的私钥文件,用于加密和身份验证。 - peer.crt:用于 Etcd 节点间的安全通信的对等证书。
- peer.key:与
peer.crt配对使用的私钥,用于节点间通信加密。 - ca.crt:CA 根证书,用于验证节点间通信时对方证书的可信度。
获取 Etcd 监控数据
了解证书文件的位置后,可以通过 curl 命令获取 Etcd 的监控数据:
默认情况下,curl 会验证 SSL/TLS 证书以确保通信的安全性。如果服务器使用的证书未被默认信任的 CA 签发,curl 会报错。可以使用 -k 选项跳过证书验证,但这会降低安全性,因此推荐使用 --cacert 指定一个受信任的 CA 证书。
例如,使用以下命令显式指定 CA 证书:
curl --cacert /etc/kubernetes/pki/etcd/ca.crt \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.key \
https://192.168.17.121:2379/metrics
通过这种方式,可以安全地获取 Etcd 的监控指标。
如果证书未被受信任的证书颁发机构(CA)签发,也可以使用 -k 或 --insecure 跳过证书验证:
curl -k \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.key \
https://192.168.17.121:2379/metrics
1. 创建 Etcd Service
首先,配置 Etcd 的 Service 和 Endpoint:
apiVersion: v1
kind: Endpoints
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.17.121 # 替换为实际 IP
ports:
- name: https-metrics # 与 ServiceMonitor 保持一致
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
spec:
ports:
- name: https-metrics # 与 ServiceMonitor 保持一致
port: 2379
protocol: TCP
targetPort: 2379
type: ClusterIP
接着,创建资源并测试 ClusterIP 的连通性:
[root@master-01 20241106]# kubectl -n kube-system get svc etcd-prom
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-prom ClusterIP 10.98.156.28 <none> 2379/TCP 2m30s
[root@master-01 20241106]# curl -k --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://192.168.17.121:2379/metrics | tail -n 3
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 159k 0 159k 0 0 1519k 0 --:--:-- --:--:-- --:--:-- 1533k
promhttp_metric_handler_requests_total{code="200"} 3
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
2. 为 Prometheus 挂载 Etcd 证书
ServiceMonitor 用于生成 Prometheus 配置文件。为了使 Prometheus 能成功获取 Etcd 的 Metrics,不仅需要知道接口地址,还需要 Etcd 的证书。因此,必须将 Etcd 证书挂载到 Prometheus 中。
首先,创建 Etcd 证书的 Secret:
kubectl -n monitoring create secret generic etcd-ssl \
--from-file=/etc/kubernetes/pki/etcd/ca.crt \
--from-file=/etc/kubernetes/pki/etcd/server.crt \
--from-file=/etc/kubernetes/pki/etcd/server.key
然后,将证书挂载到 Prometheus 容器中(如果 Prometheus 是通过 Operator 部署的,只需修改 Prometheus 资源即可):
spec:
secrets: # 添加 secrets 字段
- etcd-ssl
完成后,查看 Prometheus Pod 是否成功挂载证书:
[root@master-01 20241106]# kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
......
prometheus-k8s-0 2/2 Running 0 7m27s
prometheus-k8s-1 2/2 Running 0 7m44s
[root@master-01 20241106]# kubectl -n monitoring exec prometheus-k8s-0 -c prometheus -- ls /etc/prometheus/secrets/etcd-ssl
ca.crt
server.crt
server.key
3. 创建 Etcd ServiceMonitor
定义 ServiceMonitor 的清单文件:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd
namespace: monitoring
labels:
app: etcd
spec:
jobLabel: k8s-etcd
endpoints:
- interval: 30s
port: https-metrics # 与 Service 保持一致
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ssl/ca.crt
certFile: /etc/prometheus/secrets/etcd-ssl/server.crt
keyFile: /etc/prometheus/secrets/etcd-ssl/server.key
selector:
matchLabels:
app: etcd-prom # 与 Service 标签对应
namespaceSelector:
matchNames:
- kube-system
与之前的 ServiceMonitor 对比,多了 tlsConfig 字段,用于 HTTPS 协议的 Metric。
创建 ServiceMonitor 资源:
[root@master-01 20241106]# kubectl apply -f etcd-servicemonitor.yaml
servicemonitor.monitoring.coreos.com/etcd created
创建成功后,可在 Prometheus Web 界面查看配置:
# STATUS → Targets
4. 配置 Grafana
打开 Grafana,添加 Etcd Dashboard,依次点击:
# "+" → Import → https://grafana.com/grafana/dashboards/3070 → Load → 选择数据源 → Import
参考链接:
- 本文使用的 Dashboard 模板地址:https://grafana.com/grafana/dashboards/3070
13.3.5 非云原生应用监控
1. 部署测试用例
首先,将 MySQL 部署到 Kubernetes 集群中。如果您已经有 MySQL 部署,可以跳过此步骤:
[root@master-01 20241106]# kubectl create deploy mysql --image=registry.cn-beijing.aliyuncs.com/dotbalo/mysql:5.7.23
deployment.apps/mysql created
# 设置 MySQL root 密码(如果未设置密码会报错)
[root@master-01 20241106]# kubectl set env deploy mysql MYSQL_ROOT_PASSWORD=mysql
deployment.apps/mysql env updated
[root@master-01 20241106]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-d869bcc87-spg92 1/1 Running 0 10s
接下来,创建 MySQL 的 Service:
[root@master-01 20241106]# kubectl expose deploy mysql --port 3306
service/mysql exposed
[root@master-01 20241106]# kubectl get svc -l app=mysql
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.103.76.122 <none> 3306/TCP 13s
expose 命令将创建一个新的 Service,使 MySQL Deployment 可通过端口 3306 访问。
然后,验证 Service 是否可用:
[root@master-01 20241106]# kubectl get svc -l app=mysql
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.103.76.122 <none> 3306/TCP 3m42s
[root@master-01 20241106]# mysql -h 10.103.76.122 -uroot
ERROR 1045 (28000): Access denied for user 'root'@'172.16.184.64' (using password: NO)
[root@master-01 20241106]# mysql -h 10.103.76.122 -uroot -p
最后,登录 MySQL 创建用于 Exporter 的用户及权限:
[root@master-01 20241106]# kubectl exec -it mysql-d869bcc87-spg92 -- bash
root@mysql-d869bcc87-spg92:/# mysql -h127.0.0.1 -uroot -P3306 -p
Enter password:
mysql> CREATE USER 'exporter'@'%' IDENTIFIED BY 'exporter';
mysql> ALTER USER 'exporter'@'%' WITH MAX_USER_CONNECTIONS 3;
mysql> GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';
mysql> quit
2. 配置 MySQL Exporter
首先,定义 MySQL Exporter 的资源清单:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
k8s-app: mysql-exporter
template:
metadata:
labels:
k8s-app: mysql-exporter
spec:
containers:
- name: mysql-exporter
image: registry.cn-beijing.aliyuncs.com/dotbalo/mysqld-exporter
env:
- name: DATA_SOURCE_NAME
value: "exporter:exporter@(mysql.default:3306)/"
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9104
---
apiVersion: v1
kind: Service
metadata:
name: mysql-exporter
namespace: monitoring
labels:
k8s-app: mysql-exporter
spec:
type: ClusterIP
selector:
k8s-app: mysql-exporter
ports:
- name: api
port: 9104
protocol: TCP
注意:确保 DATA_SOURCE_NAME 环境变量配置正确,以便 Exporter 能连接到 MySQL,否则可能导致 Grafana Dashboard 无数据展示。
ENV 的配置格式:
name: DATA_SOURCE_NAME:这个环境变量名是DATA_SOURCE_NAME,它告诉容器如何连接到 MySQL 数据库。value: "exporter:exporter@(mysql.default:3306)/":这是环境变量的值,它提供了连接 MySQL 数据库的连接字符串。具体解释如下:exporter:exporter:这部分是 MySQL 数据库的用户名和密码,格式为username:password。在这个例子中,用户名是exporter,密码是exporter。mysql.default:3306:这是 MySQL 服务的主机名和端口。mysql.default是 Kubernetes 中mysql服务的 DNS 名称,3306是 MySQL 的默认端口。/:连接字符串的结尾部分,通常表示数据库名称。在这里它为空,意味着 MySQL exporter 会监控所有数据库。
接下来,创建资源:
[root@master-01 20241106]# kubectl apply -f mysql-exporter.yaml
deployment.apps/mysql-exporter created
service/mysql-exporter created
[root@master-01 20241106]# kubectl get svc -n monitoring |grep mysql
mysql-exporter ClusterIP 10.107.15.114 <none> 9104/TCP 8m14s
最后,检查 Metrics 是否正常:
[root@master-01 20241106]# curl -s 10.107.15.114:9104/metrics | tail -n 3
promhttp_metric_handler_requests_total{code="200"} 2
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
3. 配置 ServiceMonitor
首先,配置 ServiceMonitor 用于监控 MySQL Exporter:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: mysql-exporter
namespace: monitoring
labels:
k8s-app: mysql-exporter
spec:
jobLabel: k8s-app
endpoints:
- port: api
interval: 30s
scheme: http
selector:
matchLabels:
k8s-app: mysql-exporter
namespaceSelector:
matchNames:
- monitoring
然后,创建资源:
[root@master-01 20241106]# kubectl apply -f mysql-sm.yaml
servicemonitor.monitoring.coreos.com/mysql-exporter created
最后,在 Prometheus Web UI 中检查监控数据:
# STATUS → Targets → serviceMonitor/monitoring/mysql-exporter
4. 配置 Grafana
在 Grafana 中导入 MySQL Dashboard:
# "+" → Import → https://grafana.com/grafana/dashboards/6239 → Load → 选择数据源 → Import
参考链接:
- 使用的 Dashboard 模板:https://grafana.com/grafana/dashboards/6239
13.4 黑盒监控
13.4.1 黑盒监控与白盒监控
黑盒监控(Black-box Monitoring)和白盒监控(White-box Monitoring)是两种常见的监控方法,它们在监控深度、数据收集方式以及对系统内部了解的程度上有所不同。
白盒监控 关注系统内部,主要用于诊断问题的根本原因。它通过访问源代码、系统日志、应用性能数据和硬件资源使用情况,提供更精确的监控信息。通常,Etcd 和 MySQL 的监控属于白盒监控。
黑盒监控 则关注系统外部的表现,主要是通过用户视角观察正在发生的问题,例如网站变慢或无法访问等现象。黑盒监控不涉及系统内部实现,监控工具通过观察系统的外部响应来评估健康状况。
黑盒监控与白盒监控比较:
| 特性 | 黑盒监控 (Black-box) | 白盒监控 (White-box) |
|---|---|---|
| 监控焦点 | 外部表现(响应时间、可用性等) | 内部数据(资源使用、应用性能等) |
| 深入程度 | 浅(关注外部行为) | 深(深入应用和基础设施) |
| 权限要求 | 不需要访问内部(仅关注外部接口) | 需要访问源代码、日志和配置等内部数据 |
| 适用场景 | 用户体验、系统可用性监控 | 性能调优、故障诊断、应用监控 |
| 实施难度 | 简单,易于实现 | 需要更多的系统集成与开发支持 |
15.4.2 黑盒监控初体验
白盒监控和黑盒监控都可以通过 Exporter 采集数据。最新版本的 Kube Prometheus Stack 默认安装了 BlackBox Exporter,可用于采集域名、接口或 TCP 连接的状态信息。
通过以下命令查看 BlackBox Exporter 状态:
[root@master-01 ~]# kubectl -n monitoring get pod -l app.kubernetes.io/name=blackbox-exporter
NAME READY STATUS RESTARTS AGE
blackbox-exporter-746c64fd88-7z64l 3/3 Running 27 (79m ago) 3d17h
[root@master-01 ~]# kubectl -n monitoring get svc -l app.kubernetes.io/name=blackbox-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blackbox-exporter ClusterIP 10.107.125.245 <none> 9115/TCP,19115/TCP 6d
同时,它会创建一个 Service,可以通过该 Service 访问 BlackBox Exporter 并传递参数。例如,检测 www.lxfblog.xyz/tags/kubernetes 网站状态的命令如下:
[root@master-01 ~]# curl -s "http://10.107.125.245:19115/probe?target=www.lxfblog.xyz/tags/kubernetes&module=http_2xx" | tail -1
probe_tls_version_info{version="TLS 1.2"} 1
其中,probe 是接口地址,target 是检测目标,module 是探测模块。
参考链接:
- BlackBox Exporter Install:https://github.com/prometheus/blackbox_exporter
13.5 Prometheus 静态配置
在之前的配置中,监控目标使用了 ServiceMonitor,但它可能有一些限制。例如,如果没有安装 Prometheus Operator,ServiceMonitor 将无法使用。此外,并非所有监控都适合通过 ServiceMonitor 配置,或者使用 ServiceMonitor 配置会显得过于繁琐。
上节内容中,黑盒监控使用 ServiceMonitor 配置显得较为复杂。相比之下,使用传统的静态配置方式直接将 target 传递给 BlackBox Exporter 更加简便。虽然本文中 Prometheus 是通过 Operator 安装的,但它同样支持静态配置,可以通过以下步骤启用 Prometheus 的静态配置。
首先,创建一个空文件,并通过该文件创建 Secret,作为 Prometheus 的静态配置:
[root@master-01 20241106]# touch prometheus-additional.yaml
[root@master-01 20241106]# kubectl create secret generic additonal-configs --from-file=prometheus-additional.yaml -n monitoring
secret/additonal-configs created
创建 Secret 后,编辑 Prometheus 配置:
[root@master-01 20241106]# kubectl -n monitoring edit prometheus k8s
……
spec:
……
image: quay.io/prometheus/prometheus:v2.36.1
additionalScrapeConfigs:
key: prometheus-additional.yaml
name: additional-configs
optional: true
保存后,配置立即生效,无需重启 Prometheus Pod。
然后编辑 prometheus-additional.yaml 文件,配置静态配置(以黑盒监控为例):
vim prometheus-additional.yaml
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response
static_configs:
- targets:
- https://www.lxfblog.xyz/tags/kubernetes # 监听的网站1
- https://www.baidu.com # 监听的网站2
relabel_configs:
- source_labels: [__address__]
target_label: __param_target # 将 __address__ 的值映射到 __param_target
- source_labels: [__param_target]
target_label: instance # 将 __param_target 的值映射到 instance 标签
- target_label: __address__
replacement: blackbox-exporter:19115 # 设置 __address__ 为 blackbox-exporter 地址
解释:
job_name: 'blackbox':指定监控任务名称。metrics_path: /probe:Prometheus 请求的指标路径。params: module: [http_2xx]:使用http_2xx模块检查 HTTP 200 状态。static_configs:配置监控目标。relabel_configs:配置标签映射。
编辑后,通过以下命令更新 Secret:
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml --dry-run=client -o yaml | kubectl apply -f - -n monitoring
更新后,在 Prometheus Web UI 中可以查看配置:
# Status → Targets → blackbox(job_name字段配置的任务名称)
在 Grafana 中导入黑盒监控模板:
# "+" → Import → https://grafana.com/grafana/dashboards/13659 → Load → 选择数据源 → Import
此方法适用于 HTTP 模块,其他模块配置相似,参考:Blackbox Exporter。
13.6 Prometheus 监控 Windows 主机
1. 首先下载并安装对应的 Exporter 至 WIndows 主机
下载地址:https://github.com/prometheus-community/windows_exporter
安装好之后 Windows Exporter 会暴露一个 9182 端口
2. 为 Prometheus 配置 job
在15.5 的配置文件中增加以下内容:
- job_name: 'WindowsExporterMonitor'
static_configs:
- targets:
- "1.1.1.1:9182" # 替换为被监控的 Windows 主机的 IP 和端口
labels:
server_type: "windows"
relabel_configs:
- source_labels: [__address__]
target_label: instance
targets 配置的是健康共的主机,如果有多台 Windows 主机,配置多行即可,当然每台主机都需要配置 Exporter
3. Grafana 导入 Dashboard 模板
模板地址:https://grafana.com/grafana/dashboards/12566
13.7 Prometheus 语法 PromQL
13.7.1 PromQL 语法初体验
Prometheus 查询语法称为 PromQL,类似于 MySQL 的 SQL 语句。首先使用查询语法获取所需数据,然后根据条件判断执行告警等操作。Prometheus 的 Web UI 中,Graph 菜单提供了一个简单的入口,用于编写和校验 PromQL 查询语法。
例如,输入 up 并点击 Execute,可以查看到所有正常监控的目标:
up
查询结果示例如下:
up{container="alertmanager", endpoint="web", instance="172.16.171.21:9093", job="alertmanager-main", namespace="monitoring", pod="alertmanager-main-1", service="alertmanager-main"} 1
……
1. 标签选择器与过滤
up 命令会返回所有正常监控的目标。如果监控目标较多,可能会返回大量数据。此时,可以通过条件过滤来缩小结果范围,类似于 SQL 的 WHERE 子句。例如,使用标签选择器筛选出 job 为 node-exporter 的目标:
up{job="node-exporter"}
查询结果可能类似于:
up{container="kube-rbac-proxy", endpoint="https", instance="master-01", job="node-exporter", namespace="monitoring", pod="node-exporter-4z9dg", service="node-exporter"} 1
up{container="kube-rbac-proxy", endpoint="https", instance="worker-01", job="node-exporter", namespace="monitoring", pod="node-exporter-r5r76", service="node-exporter"} 1
2. 常见运算符与匹配方式
注意,up{job="node-exporter"} 进行的是精确匹配。PromQL 还支持以下运算符:
!=:表示不等于某个值的指标,例如up{job!="node-exporter"},表示job不为node-exporter的指标。=~:表示符合正则表达式的指标,例如up{job=~"node.*"},表示job以node开头的指标。!~:与=~类似,但表示正则不匹配,即排除一些指标。
示例
若要查看主机监控的所有指标,可以输入 node,这会列出所有主机相关的监控指标。
例如,若要查询 Kubernetes 集群中每个宿主机的磁盘总量,可以使用:
node_filesystem_size_bytes
如果返回的数据量较大,可以通过进一步的过滤进行处理,例如仅查询根分区的大小,使用前述的标签选择器加上 mountpoint 匹配规则:
node_filesystem_size_bytes{mountpoint="/"}
或者,查询分区不是 /boot 且磁盘设备以 /dev/ 开头的分区大小:
node_filesystem_size_bytes{device=~"/dev/.*",mountpoint!="/boot"}
3. 瞬时向量与区间向量
上述 PromQL 查询返回的是瞬时值,即 Prometheus 采集到的最新数据,称为 瞬时向量。作为一个时序数据库,Prometheus 也支持查询某个指标在一段时间内的数据。
例如,要查看主机 master-01 在最近 5 分钟内的可用磁盘空间变化:
node_filesystem_size_avail_bytes{instance="master-01",mountpoint="/",device="/dev/mapper/centos-root"} [5m]
查询结果示例:
12453838848 @1731429273.823
12453838848 @1731429288.823
12453838848 @1731429303.823
12453818368 @1731429318.823
12453838848 @1731429333.823
12453838848 @1731429348.823
12453838848 @1731429363.823
12453818368 @1731429378.823
12453818368 @1731429393.823
12453818368 @1731429408.823
12453838848 @1731429423.823
12453838848 @1731429438.823
12453818368 @1731429453.823
12453818368 @1731429468.823
12453818368 @1731429483.823
12453838848 @1731429498.823
12449607680 @1731429513.823
12449624064 @1731429528.823
12449624064 @1731429543.823
12451717120 @1731429558.823
每条数据记录后都带有一个时间戳(@ 后面的部分),表示数据采集的时间。可以看到,在 5 分钟内,返回了多个数据点。这类查询称为 区间向量,其查询结果可使用时间单位:秒(s)、分钟(m)、小时(h)、天(d)、周(w)和年(y)。
node_filesystem_size_avail_bytes{instance="master-01",mountpoint="/",device="/dev/mapper/centos-root"} [5s]
node_filesystem_size_avail_bytes{instance="master-01",mountpoint="/",device="/dev/mapper/centos-root"} [5h]
4. 偏移量查询
此外,Prometheus 还支持查询 偏移量 数据。例如,要查询 10 分钟前的磁盘可用空间:
node_filesystem_avail_bytes{instance="master-01",mountpoint="/"} offset 10m
或者查询过去 10 分钟前,5 分钟区间的磁盘可用空间变化:
node_filesystem_avail_bytes{instance="master-01",mountpoint="/"}[5m] offset 10m
13.7.2 PromQL 操作符
PromQL 支持对查询出来的数据进行再计算。您可以将查询结果作为表达式的一部分,进行进一步的数学运算或逻辑处理。这种灵活性是 PromQL 强大的原因之一,可以在同一查询中完成多个操作。
1. 数学运算符
PromQL 支持多种数学运算符,可以在查询中灵活使用。常见的运算符包括:
+:加法-:减法*:乘法/:除法^:幂运算%:求余
PromQL 查询默认返回的数据单位通常为字节(bytes)。为了便于阅读,可以将字节数转换为更易懂的单位(如 GB 或 MB)。以下是将字节转换为 GB 的示例:
node_filesystem_avail_bytes{instance="master-01", mountpoint="/", device="/dev/mapper/centos-root"} / 1024 / 1024 / 1024
或者,您也可以使用简化的表达方式:
node_filesystem_avail_bytes{instance="master-01", mountpoint="/", device="/dev/mapper/centos-root"} / (1024^3)
可以在宿主机上运行以下命令对比实际数据:
df -Th
# -T 选项用于显示文件系统类型
查询特定主机根分区的磁盘可用率,可以使用以下查询:
node_filesystem_avail_bytes{instance="master-01", mountpoint="/", device="/dev/mapper/centos-root"} / node_filesystem_size_bytes{instance="master-01", mountpoint="/", device="/dev/mapper/centos-root"}
其中,node_filesystem_avail_bytes 代表磁盘可用空间,node_filesystem_size_bytes 代表磁盘总空间。
如果要查询所有主机的根分区可用率,可以去掉 instance 参数:
node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}
若希望直接返回百分比,可将查询结果乘以 100:
(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100
2. 比较运算符
PromQL 提供多种比较运算符,您可以根据需要灵活地调整查询条件:
==:相等!=:不相等>:大于<:小于>=:大于等于<=:小于等于
例如,要查询磁盘可用率大于 60% 的主机,可以使用以下查询:
(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 > 60
如果需要查询磁盘可用率介于 30% 到 60% 之间的主机,可以使用:
30 < (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 <= 60
当查询条件较多时,可以通过 and 运算符将多个条件联合在一起。例如,查询磁盘可用率在 30% 到 60% 之间的主机,可以使用:
30 < (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 and (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}) * 100 <= 60
3. and、or 和 unless 关键字
PromQL 还支持以下关键字来进一步精细化查询:
and:满足所有条件or:满足任一条件unless:排除特定条件
例如,如果要查询主机磁盘剩余空间,但排除 shm 和 tmpfs 设备的磁盘,可以使用:
node_filesystem_free_size_bytes unless node_filesystem_free_bytes{device=~"shm|tmpfs"}
或者,可以简化为:
node_filesystem_free_size_bytes{device!~"shm|tmpfs"}
通过合理组合这些运算符和关键字,可以根据需求灵活地调整 PromQL 查询,从而高效地获取所需的监控数据。
13.7.3 PromQL 常用函数
PromQL 提供了多种内置函数,帮助我们对监控数据进行更复杂的处理和分析。这些函数可以对时间序列数据进行聚合、转换、数学运算、统计分析等操作。
1. sum
sum 函数用于计算指定时间范围内所有时间序列的总和,常用于聚合指标数据。
示例 1:计算所有主机根分区剩余的空间总和(单位:GB)
sum(node_filesystem_free_bytes{mountpoint="/"}) / 1024^3
示例 2:统计所有 Kubernetes 节点的 HTTP 请求总数
sum(kubelet_http_requests_total)
2. topk
topk 函数返回前 k 个时间序列,通常用于找出具有最高值的时间序列。
示例:找出前 5 个 HTTP 请求数最多的节点:
topk(5, sum(kubelet_http_requests_total) by (node))
3. min
min 函数返回指定时间序列中的最小值。
示例:获取所有 Kubernetes 节点中 CPU 使用率的最小值:
min(node_cpu_seconds_total{mode="user"}) by (node)
4. max
max 函数返回指定时间序列中的最大值。
示例:获取所有 Kubernetes 节点中 CPU 使用率的最大值:
max(node_cpu_seconds_total{mode="user"}) by (node)
5. avg
avg 函数用于计算指定时间序列的平均值。
示例:获取所有节点的平均 CPU 使用率:
avg(node_cpu_seconds_total{mode="user"}) by (node)
6. ceil
ceil 函数将值向上舍入为最接近的整数。
示例:将磁盘空间使用量向上舍入为最接近的整数(单位:GB):
ceil(node_filesystem_size_bytes{mountpoint="/"} / 1024^3)
7. floor
floor 函数将值向下舍入为最接近的整数。
示例:将磁盘使用量向下舍入为最接近的整数(单位:GB):
floor(node_filesystem_free_bytes{mountpoint="/"} / 1024^3)
8. sort
sort 函数按升序对时间序列进行排序。
示例:按升序排列 CPU 使用时间(user 模式):
sort(node_cpu_seconds_total{mode="user"})
9. sort_desc
sort_desc 函数按降序对时间序列进行排序。
示例:按降序排列所有节点的 HTTP 请求数:
sort_desc(sum(kubelet_http_requests_total) by (node))
10. predict_linear
predict_linear 函数基于现有数据对未来一段时间的值进行线性预测。
示例:预测未来 1 小时根目录的磁盘使用情况:
ceil(predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h], 3600) / 1024^3)
11. increase
increase 用于计算在指定时间范围内数据的增长。
示例:计算过去 5 分钟内磁盘写入的字节数增量:
increase(node_disk_written_bytes_total[5m])
12. rate
rate 计算一个时间区间内的平均速率。它对时间区间内的增量进行平滑处理,适合长期趋势分析。
示例:计算过去 1 分钟内磁盘写入速率(单位:字节/秒):
rate(node_disk_written_bytes_total[1m])
使用 rate 和 increase 时,可能会遇到长尾效应,即某个指标长时间未变化,导致计算结果为 0。比如磁盘空间已经达到 100%,过去 1 小时内没有变化,查询的增长率就为 0,容易产生误判。此时,可以使用 irate 来解决这一问题。
13. irate
irate 计算时间区间内的瞬时速率,只考虑最近两个数据点的增量,适合观察短期波动。
示例:计算过去 1 分钟内磁盘写入的即时速率(单位:字节/秒):
irate(node_disk_written_bytes_total[1m])
注意事项:irate 函数的参数(比如 [1m])其实并没有太大意义,因为 irate 只会考虑查询时间范围内的 最后两个数据点 来计算瞬时速率。也就是说无论你使用的是 irate(http_requests_total[1m]) 还是 irate(http_requests_total[5m]),Prometheus 只会使用最后两个数据点 来计算速率。
总结
sum、avg、max等函数常用于聚合数据,帮助分析整体趋势。topk和sort_desc等函数适合用于查找具有最大或最小值的时间序列。increase和rate适用于计算数据的增量或速率,但可能会遇到长尾效应,需要使用irate来解决零增长的问题。
13.8 Alertmanager 告警
13.8.1 Prometheus 的告警原理
当 Prometheus 监控的数据满足告警规则时,Prometheus 和 Alertmanager 的工作流程可以分为以下几个阶段:
1. Prometheus 收集数据并评估告警规则
Prometheus 定期抓取监控数据,根据告警规则(如阈值、持续时间等)评估数据。如果数据符合告警条件,Prometheus 触发告警。
2. Prometheus 将告警发送给 Alertmanager
Prometheus 将触发的告警通过 HTTP 请求发送到 Alertmanager。
3. Alertmanager 处理告警
Alertmanager 根据告警标签将其发送到对应的接收器(如邮件、Slack)。
4. Alertmanager 发送通知
根据配置,Alertmanager 通过邮件、Slack 等渠道将告警通知给相关人员。
5. 告警恢复
当告警条件恢复正常时,Prometheus 更新告警状态为“已恢复”并通知 Alertmanager。
Alertmanager 如果配置了恢复通知,会将恢复信息发送给相关人员。
13.8.2 Alertmanager 配置文件解析
1. 配置文件总览
首先看一个 Alertmanager 的配置文件示例:
以下是一个相对完整的 Alertmanager 配置文件示例,包含了常见的功能设置,如告警路由、通知接收器、分组、抑制等:
# 全局设置
global:
# 设置全球配置,比如SMTP服务器
smtp_smarthost: 'smtp.example.com:587' # 邮件服务器
smtp_from: 'alertmanager@example.com' # 发件人地址
smtp_auth_username: 'username' # 邮件认证用户名
smtp_auth_password: 'password' # 邮件认证密码
smtp_require_tls: true # 启用TLS加密
# 告警路由配置
route:
# 根路由
receiver: 'email' # 默认的接收器
group_by: ['alertname', 'priority'] # 将这些标签合并成一个通知
group_wait: 30s # 发送第一次通知前等待的时间
group_interval: 5m # 同组告警间隔,防止重复通知
repeat_interval: 3h # 重复告警的最小间隔
# 路由规则
routes:
- match:
severity: 'critical' # 匹配严重告警
receiver: 'slack-critical' # 发送到 Slack
group_by: ['alertname'] # 按照警报名称分组
group_wait: 10s
group_interval: 2m
- match:
severity: 'warning' # 匹配警告告警
receiver: 'email-warning' # 发送到邮件
group_wait: 5s
group_interval: 1m
# 告警接收器配置
receivers:
- name: 'email'
email_configs:
- to: 'admin@example.com'
send_resolved: true # 发送恢复通知
- name: 'email-warning'
email_configs:
- to: 'ops-team@example.com'
send_resolved: true
- name: 'slack-critical'
slack_configs:
- api_url: 'https://hooks.slack.com/services/xxx/yyy/zzz'
channel: '#critical-alerts'
send_resolved: true
# 默认为空的抑制规则
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# 当“critical”告警存在时,抑制“warning”告警
equal: ['alertname', 'instance']
# 配置外部 webhook 接收器
webhook_configs:
- url: 'http://example.com/webhook'
send_resolved: true # 发送恢复通知
# 自定义模板设置
templates: {}
从配置文件中可以看出,Alertmanager 的配置主要分为五个部分:
- Global(全局设置):用于配置通用选项,如邮件通知的账号、密码、SMTP 服务器、微信告警等。Global 部分的配置对整个文件有效,但其他部分的配置可以覆盖 Global 配置。
- Route(告警路由配置):负责将告警信息按规则进行分组和路由,以便不同类型的告警可以发送到不同的收件人。例如,可以将数据库告警发送给 DBA,将服务器告警发送给 OPS。
- Receivers(告警接收人配置):定义告警的接收者,每个接收器都有一个唯一名称。经过路由分组后,告警会发送到相应的接收器,这部分配置了告警的具体接收渠道。
- Inhibit Rules(告警抑制规则):用于减少告警数量,避免“告警轰炸”。例如,当宿主机宕机时,可能会引发一系列其他问题(如容器重建、服务不可用等),如果每个异常都生成告警,会造成信息过载并干扰问题的定位。通过告警抑制,只发送最关键的告警(如宿主机宕机),避免其他告警的干扰。
- Templates(模板配置):用于存放自定义告警模板的位置,方便用户根据实际需求进行定制。
2. 路由规则 Route 块
Route 是告警的路由配置,允许根据告警的标签将其发送到特定的接收者或小组。此配置是 Alertmanager 中最为复杂且经常变化的部分。
route:
receiver: Default # 默认接收器,若没有匹配的子路由则使用此接收器
group_by: # 告警分组字段,常用的有命名空间、任务、告警名称等
- namespace
- job
- alertname
routes:
- receiver: Watchdog # 'alertname' 为 'Watchdog' 时,告警发送到 Watchdog 接收器
match:
alertname: Watchdog
- receiver: Critical # 'alertname' 为 'critical' 时,告警发送到 Critical 接收器
match:
alertname: critical
group_wait: 30s # 初次告警发送前的等待时间,主要用于告警合并
group_interval: 5m # 同一组告警的最小再次发送间隔
repeat_interval: 10m # 重新发送告警的最小间隔时间
从上述配置可以看出,route 是告警路由的入口点。每条告警会首先进入 route,然后根据告警标签和 group_by 配置的字段进行分组。比如,可以通过 job、cluster 或其他自定义标签对告警进行分组。分组后,告警会进一步匹配子路由(在 routes 中配置),进行更细粒度的分类。例如,包含 mysql 的 job 可以被路由到 DBA 小组。
除了 group_by 和 routes,Route 配置项还包括以下常用选项:
-
receiver:告警的通知目标,需与
receivers配置中的name匹配。如果没有子路由匹配,则使用route.receiver配置的默认接收器,例如上述配置中的Default。 -
group_by:告警分组字段,类型为列表。上述配置中,
group_by设置为['namespace', 'job', 'alertname'],意味着告警会根据这三个标签进行分组,并且只有在标签的key和value都相同的情况下,告警才会被归为同一组。 -
continue:决定是否在匹配到第一个路由后继续进行后续路由匹配,默认值为
false。 -
match:一对一的匹配规则。例如,
match: job: mysql表示job=mysql的告警将进入此路由。 -
match_re:正则匹配,功能与
match类似。 -
matchers:这是 Alertmanager 0.22 及以上版本新增的配置项,旨在替代
match和match_re。它允许通过类似 PromQL 的语法进行更灵活的匹配。matchers 设计理念参考了 PromQL 和 OpenMetrics,可以直接写成如下格式:匹配 foo 等于 bar ,且 dings 不等于 bums:
matchers: - too = bar - dings != bums匹配 foo 等于 bar 和 baz, 且 dings 不等于 bums:
matchers: ["foo = bar,baz", "dings != bums"]matchers: [ '{foo="bar", "dings!= "bums"}' ] -
group_wait:告警组等待时间,类型为字符串。它定义了一组新的告警产生时,等待合并后的通知发送时间,默认值为 30 秒。该功能有助于防止短时间内大量告警产生,减少告警通知的频率。
-
group_interval:同一组告警的最小再次发送间隔,默认为 5 分钟。即,如果该组有新的告警产生,告警通知会在此间隔后发送。
-
repeat_interval:如果告警在成功发送后未被解决,且在
repeat_interval指定的时间间隔后该告警仍未解决,则会重新发送告警通知。默认值为 4 小时。
Alertmanager 的路由和匹配规则非常灵活,通过嵌套的路由和不同的匹配策略,用户可以精准地控制告警的发送和通知。
13.8.3 二进制安装告警初体验
Prometheus 默认并没有开启 Alerting(告警)功能,你需要手动配置警报规则和Alertmanager来实现告警功能。Prometheus 自身主要负责收集和存储指标数据,告警系统通过定义警报规则、配置Alertmanager来完成。
假设你已经安装好 Prometheus 和 Alertmanager,下面是配置的步骤:
1. 配置 Prometheus 的告警规则(Alerting Rules)
Prometheus 的告警规则是通过 alert.rules 或其他自定义的 .yml 文件来配置的。你可以在 Prometheus 配置文件中指定告警规则文件。
在 Prometheus 配置文件(prometheus.yml)中,添加告警规则文件的路径:
rule_files:
- "rules/*rules.yaml"
创建一个规则文件,定义你的警报规则。例如,检测一个名为 http_requests_total 的 HTTP 请求总数,如果在 5 分钟内没有任何请求,则触发告警(确保有这个指标):
mkdir prometheus/rules
vim example_rules.yaml
groups:
- name: example_alert
rules:
- alert: HighRequestLatency
expr: http_requests_total{job="api", status="500"} > 100
for: 5m
labels:
severity: critical
annotations:
summary: "API requests failed with status 500 for more than 5 minutes"
alert是告警的名称。expr是 Prometheus 查询表达式,用于定义触发告警的条件。for是告警持续时间,意味着条件要持续一定时间后才会触发告警。labels和annotations用于为告警添加额外的元数据和描述。
2. 配置 Alertmanager
Alertmanager 是 Prometheus 用于处理和路由警报的组件,负责通知相应人员或者系统。你需要配置 Alertmanager 来定义如何处理和发送告警。
在 Prometheus 配置文件 prometheus.yml 中添加 Alertmanager 的地址:
alerting:
alertmanagers:
- static_configs:
- targets:
- 'localhost:9093' # 假设 Alertmanager 运行在本地的 9093 端口
配置 Alertmanager 的通知方式(如电子邮件、Slack、PagerDuty 等)。在 Alertmanager 的配置文件 alertmanager.yml 中定义接收告警的方式:
global:
# 设置全球配置,比如SMTP服务器
resolve_timeout: 5m
smtp_smarthost: 'smtp.example.com:587' # 邮件服务器
smtp_from: 'alertmanager@example.com' # 发件人地址
smtp_auth_username: 'username' # 邮件认证用户名
smtp_auth_password: 'password' # 邮件认证密码
smtp_require_tls: true # 启用TLS加密
route:
receiver: 'email_notifications'
receivers:
- name: 'email_notifications'
email_configs:
- to: 'your_email@example.com'
from: 'prometheus_alerts@example.com'
smarthost: 'smtp.example.com:587'
auth_username: 'smtp_user'
auth_password: 'smtp_password'
route用于定义告警的路由规则。receivers是告警的接收方式,例如电子邮件配置email_configs。
3. 启动 Prometheus 和 Alertmanager
确保 Prometheus 和 Alertmanager 都已经启动,并且它们之间的连接是正常的。你可以通过访问以下 URL 检查它们的状态:
- Prometheus Web 界面:
http://localhost:9090 - Alertmanager Web 界面:
http://localhost:9093
4. 测试告警
你可以手动触发告警或等待 Prometheus 收集到的数据符合告警条件,来测试告警是否正常工作。例如,通过修改 Prometheus 中的查询表达式,确保它会触发告警。
13.8.4 Alertmanager 邮件通知
告警邮件通知是企业中常用的通知方式,Alertmanager 原生支持邮件告警,且其配置较为简便。首先,进入代码目录并找到 Alertmanager 配置文件(不同安装方式的位置可能有所不同,需自行查找):
对于通过 Operator 安装的 Prometheus 和 Alertmanager,其配置存储在 Kubernetes 的 ConfigMap 和 Secret 中。Alertmanager 的配置文件通过 Secret 存储,文件名为 alertmanager-secret.yaml。
[root@master-01 ~]# cd kube-prometheus/manifests/
[root@master-01 manifests]# ls alertmanager-secret.yaml
alertmanager-secret.yaml
通常,通用配置位于 global 部分,包括 SMTP 配置。为了启用邮件发送功能,我们需要在 alertmanager-secret.yaml 文件的 global 部分添加 SMTP 服务器信息:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"smtp_from": "3211422869@qq.com"
"smtp_smarthost": "smtp.qq.com:465"
"smtp_hello": "qq.com"
"smtp_auth_username": "3211422869@qq.com"
"smtp_auth_password": "btpznhzzurvyddcd"
"smtp_require_tls": false
接下来,将名为 Default 的 receiver 配置为邮件通知作为测试,修改 alertmanager-secret.yaml 文件中的 receivers 配置:
"receivers":
- "name": "Default"
"email_configs":
- "to": "12345678901@163.com"
"send_resolved": true
- "name": "Watchdog"
- "name": "Critical"
email_configs:启用邮件通知。to:指定收件人,可以配置多个,用逗号分隔。替换为自己的收件人地址send_resolved:告警解决后是否发送通知。
此时,告警邮件通知已完成配置。接下来分析路由规则,默认情况下只按照 namespace 进行分组。我们还可以在路由中添加 job 和 alertname 标签。如下配置:
"route":
"group_by":
- "namespace"
- "job"
- "alertname"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "matchers":
- "alertname = Watchdog"
"receiver": "Watchdog"
- "matchers":
- "alertname = InfoInhibitor"
"receiver": "null"
- "matchers":
- "severity = critical"
"receiver": "Critical"
此告警规则将基于 namespace、job 和 alertname 标签进行分组。未匹配到子路由的告警默认发送给 Default 接收器;匹配到 alertname=Watchdog 的告警将发送给 Watchdog 接收器,匹配到 severity=critical 的告警则发送给 Critical 接收器。
通过 Alertmanager 提供的 Web UI 可以查看告警分组信息。为了访问 Web UI,我们可以将 Alertmanager 的 Service 类型修改为 NodePort:
[root@master-01 manifests]# kubectl -n monitoring edit svc alertmanager-main
[root@master-01 manifests]# kubectl -n monitoring get svc alertmanager-main
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.105.110.81 <none> 9093:32588/TCP,8080:32684/TCP 10d
更新 Alertmanager 配置文件:
[root@master-01 manifests]# kubectl replace -f alertmanager-secret.yaml
secret/alertmanager-main replaced
重启相关 Pod:
[root@master-01 manifests]# for i in $(kubectl -n monitoring get pod | grep alertmanager-main | awk '{print $1}'); do kubectl -n monitoring delete pod $i; done
pod "alertmanager-main-0" deleted
pod "alertmanager-main-1" deleted
pod "alertmanager-main-2" deleted
等待 Pod 重启后,可以在 Alertmanager 的 Web UI 查看更新的配置和分组信息:
# 配置查看:Status → Config
# 分组信息查看:Alertmanager → Group
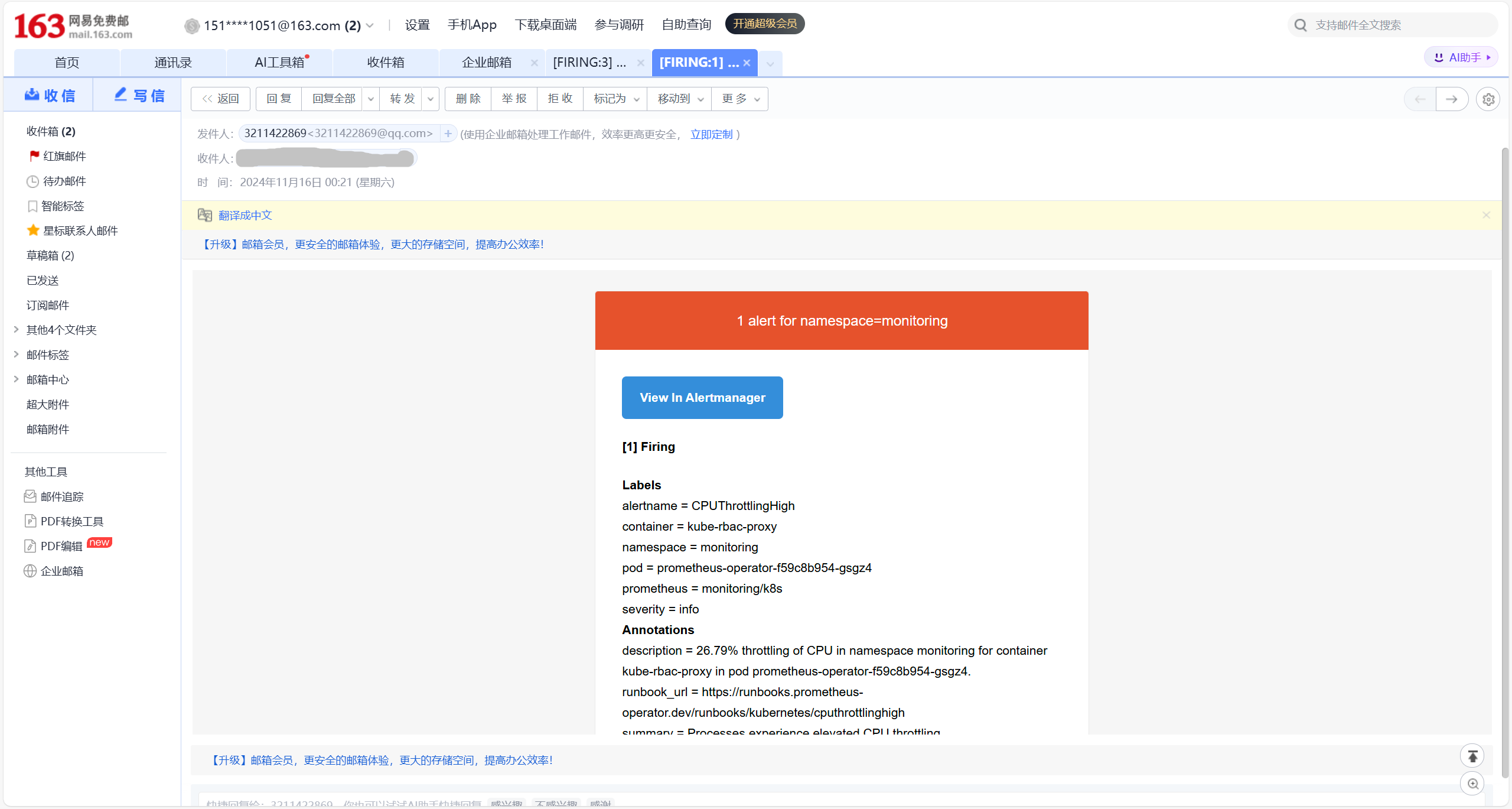
完成上述步骤后,即可通过邮箱收到告警通知。
1.3.8.5 告警规则的分组和路由
在 kube-prometheus 项目中,告警规则(Alerting Rules)是根据一些标签(labels)来进行分组和路由的。通过在 Prometheus 中定义的告警规则,可以为不同的告警分配不同的标签,这些标签将在 Alertmanager 中用于对告警进行分组和路由。
在 Prometheus 的告警规则中,可以通过设置 labels 字段来定义告警的标签。常见的标签包括 severity、alertname、namespace、job 等。以下是一个告警规则的例子:
groups:
- name: example-alerts
rules:
- alert: HighCpuUsage
expr: process_cpu_seconds_total > 100
for: 5m
labels:
severity: critical
environment: production
annotations:
summary: "High CPU usage detected"
description: "CPU usage exceeds 100 for 5 minutes."
在上面的例子中,告警规则 HighCpuUsage 被赋予了两个标签:severity: critical 和 environment: production。这些标签将帮助 Alertmanager 对告警进行分组和路由。
如何使用标签进行分组和路由
在 Alertmanager 的配置中,标签用于告警的分组(grouping)和路由(routing)。Alertmanager 会根据告警的标签来决定如何将告警发送到不同的接收器(receiver),比如邮件、Slack 或 Webhook 等。
配置告警分组
在 alertmanager.yaml 中,使用 group_by 来指定分组规则。告警会根据这些标签进行分组。
例如:
route:
group_by: ['alertname', 'severity', 'namespace'] # 按照 alertname、severity 和 namespace 标签分组
group_interval: 5m
group_wait: 30s
receiver: 'default-receiver'
在上面的配置中,告警会根据 alertname、severity 和 namespace 标签进行分组。group_by 数组定义了分组的维度。
配置告警路由
路由规则可以根据告警的标签来决定告警发送到哪个接收器(receiver)。例如,某些告警可能需要发送到邮件,另一些可能发送到 Slack。
receivers:
- name: 'default-receiver'
email_configs:
- to: 'alert@example.com'
send_resolved: true
- name: 'critical-receiver'
email_configs:
- to: 'critical-alerts@example.com'
send_resolved: false
route:
group_by: ['alertname', 'severity', 'namespace']
receiver: 'default-receiver'
routes:
- match:
severity: 'critical'
receiver: 'critical-receiver'
在上面的配置中,所有告警会先发送到 default-receiver,但是如果告警的 severity 标签为 critical,则会被路由到 critical-receiver,并发送到指定的邮箱。
评论区